MapReduce 框架基础
MapReduce 介绍
MapReduce 是一种分布式计算框架,旨在处理和生成大数据集,通常运行在 Hadoop 之上。它将复杂的数据处理任务分解为两个阶段:Map 阶段 和 Reduce 阶段。
引入 MapReduce 编程模型概念:
- 目前大数据是传统数据处理单元难以处理的巨大数据负载。在计算机网络中并行工作,寻找大数据处理的解决方案成为必需趋势。
- MapReduce 编程模型,它允许我们执行并行计算,而无需担心可靠性、容错性等问题。
- 因此,MapReduce 使得我们灵活地编写代码,而无需系统的设计问题。
什么是 MapReduce ?
MapReduce 是一个编程框架,它允许我们在分布式环境中对大数据集进行分布式并行处理。
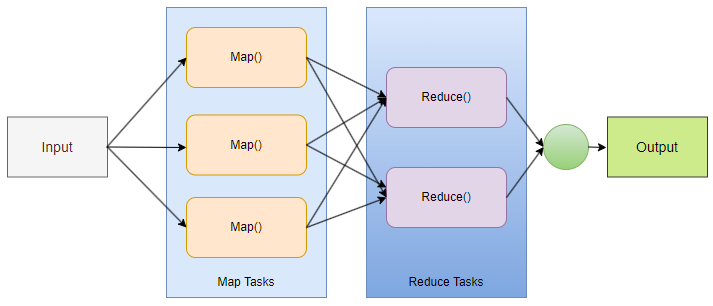
- MapReduce 由两个不同的任务组成:Map 和 Reduce。
- 正如 MapReduce 其名亦可知,reduce 阶段发生在 mapper 阶段完成之后。
- 因此,第一个任务是映射作业,其中读取并处理数据块以生成键值对作为中间输出。
- 第二个任务是 Mapper 或映射作业的输出(键值对)被输入到 Reducer。
- Reducer 从多个映射作业接收键值对。
- 最后,Reducer 将这些中间数据元组(中间键值对)聚合成较小的元组或键值对集合,作为最终输出。
Mapper 类
使用 MapReduce 进行数据处理的第一个阶段是 Mapper 类。RecordReader 处理每个输入记录并生成相应的键值对。Hadoop 的 Mapper 会存储这些中间数据到本地磁盘。
- Input Split
- 它是数据的逻辑表示。它代表一个工作块,其中,包含 MapReduce 程序中的单个映射任务。
- RecordReader
- 它与 Input Split 交互,将获得的数据转化为键值对的形式。
Reducer 类
Mapper 生成的中间输出被输入到 Reducer,Reducer 对其进行处理并生成最终输出结果,然后将其保存在 HDFS 中。
驱动类
MapReduce 作用中的主要组件是驱动程序类。它负责设置 MapReduce 作业在 Hadoop 中运行。我们指定 Mapper 和 Reducer 类的名称以及数据类型及其它们各自的作业名称。
MapReduce 工作原理
MapReduce 字数统计示例,有一个 input.txt 文本文件,其内容如下:
Dear, Bear, River, Car, Car, River, Deer, Car and Bear
假设,现在我们需要使用 MapReduce 对 input.txt 文本内容进行字数统计。我们将找到每个单词以及这些单词出现的次数。

- 首先,将输入分成三部分,以便在所有数据节点上分配工作。
- 然后,对每个映射器中的单词进行标记,为单词赋予硬编码值。硬编码值为
1表示该单词出现过一次。以此类推。 - 这样,创建一个键值对列表,其中 键是单个单词,值是单词出现过的次数。因此,对应第一行数据 (Dear Bear River),有 3 个键值对:(Dear,1)、(Bear,1)、(River,1) 。映射过程在所有节点上保持相同。
- 在映射器阶段后,会发生分区过程,进行排序和混洗,以便将所有具有相同键的所有元组发送到相应的 Reducer。
- 在分区过程之后,每个 Reducer 将具有一个唯一的键和该键相对应的值列表。如:
Bear,[1,1];Car,[1,1,1];Deer,[1,1];River,[1,1]。 - 现在,每个 Reducer 都会计算键值对中值列表的数据。如图,Reducing 获取
Bear,[1,1]将得到结果Bear,2;Car,[1,1,1]将得到结果Car,3。 - 最后,将收集所有键值对并写入输出文件中。
MapReduce 优点
MapReduce 两大优点:
-
并行处理
在 MapReduce 中,我们可以将作业分配给多个节点,每个节点同时处理其中的一部分任务。所以,MapReduce 是基于分而治之的范式,可以帮助我们使用不同的机器分布式的处理数据。
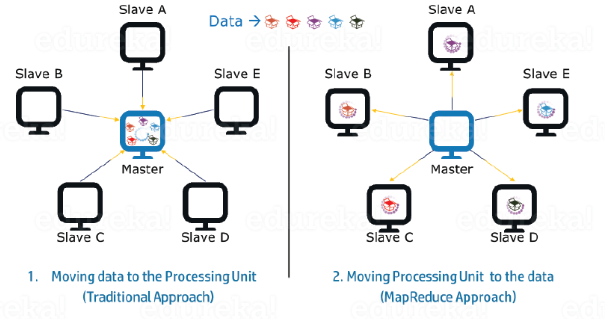
传统方式和基于 MapReduce 方式对比:
-
数据处理位置
在传统系统中,数据一般是带到处理单元并进行处理的。但随着数据大量增长,会找出以下问题:
- 将大量数据移至到处理单元成本昂贵,且降低网络性能。
- 数据由单个处理单元处理,数据处理耗时时会成为瓶颈。
- 主节点可能会因为负载而发生故障。
而 MapReduce 通过将处理单元带入数据,可以克服以上问题。因为数据分布在多个节点中,每个节点处理驻留在其上面的部分数据。
- 这样所有节点都可以并行处理器部分数据,减少处理时间。
- 每个节点获取一部分数据处理,节点也不会负担过重。
MapReduce 程序
MapReduce 程序一般分为三个部分:
- 映射阶段代码
- 合并阶段代码
- 驱动程序代码
预处理的 input.txt 文本内容:
Key Value
0 Dear Bear River
1 Car Car River
2 Deer Car Bear
映射器代码
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
解读:这部分代码是将输入的文本数据进行分词,并将每个单词作为键,计数值 1 作为值发送给 Reducer 进行进一步处理。
Mapper<LongWritable, Text, Text, IntWritable>在 Hadoop 的 MapReduce 中,Mapper 类的泛型类型指定了输入键和输入值,输出键和输出值。- 此例中,输入键是行偏移量;输入值是
Text类型的一行文本数据;输出键是Text类型的单词;输出值表示单词的计数。 - 输出键和输出值与 Context 类构造参数相对应。
- 此例中,输入键是行偏移量;输入值是
map(LongWritable key, Text value, Context context)指定了一个输入键 key、一个输入值 value 和一个上下文对象 context。LongWritable key:这是输入键的类型。在Map阶段,键表示偏移量(offset),通常用于表示输入文件中的行号。这个偏移量可以用来唯一标识文件中的每一行。这样的设计使得 MapReduce 可以并行处理文件的不同部分。Text value:这是输入值的类型。在Map阶段,值表示输入的一行文本数据。
new StringTokenizer(line)使用 StringTokenizer 对输入行进行分词。- StringTokenizer 是 Java 中的工具类,可以将字符串安装指定分隔符进行分割。默认分隔符使用空格(包括空格、制表符、换行符等空白字符)。如果自定义指定分隔符,使用 StringTokenizer 另一个构造函数,如指定分隔符为逗号
,:StringTokenizer tokenizer = new StringTokenizer(line, ",");
- StringTokenizer 是 Java 中的工具类,可以将字符串安装指定分隔符进行分割。默认分隔符使用空格(包括空格、制表符、换行符等空白字符)。如果自定义指定分隔符,使用 StringTokenizer 另一个构造函数,如指定分隔符为逗号
value.set(tokenizer.nextToken());将当前单词设置为输出键。context.write(value, new IntWritable(1));将当前单词和一个计数值1发送给 Reducer。Reducer 会对相同的单词进行合并和计数。new IntWritable(1):创建了一个新的IntWritable对象,用于表示整数值。在 MapReduce 中,IntWritable是一种 Hadoop 数据类型,用于表示整数值。它是一个[[../数据库/未命名]],可以在 Map 和 Reduce 阶段之间进行传递。
简化器代码
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWriable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable x: values)
{
sum += x.get();
}
context.write(key, new IntWritable(sum));
}
}
解读:
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>:这一行定义了一个名为Reduce的静态内部类,并声明了它的泛型类型。public void reduce(Text key, Iterable<IntWritable> values, Context context):它重写了 Reducer 类中的reduce方法,并且接受三个参数:键、值的 Iterable 迭代器以及上下文对象。Iterable<IntWritable> values表示一个能够被迭代的集合values,其中的每个元素都是IntWritable类型的对象。在这个上下文中,它代表了 Reduce 阶段中与特定键关联的所有值的集合。
IntWritable x: values其中,变量x表示迭代器values中的每个元素,每个元素都是IntWritable类型的对象。
驱动程序代码
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
解读:
new Configuration();:用于存储 Hadoop 集群的配置信息。这个对象包含了一系列键值对,用于配置 Hadoop 作业运行的环境和参数。Job.getInstance(conf, "My Word Count Program");:创建一个Job对象,表示一个 MapReduce 作业。指定作业的名称为"My Word Count Program"。job.setJarByClass(WordCount.class);:设置作业运行时使用的 Jar 文件。WordCount.class指定了包含main方法的类,这个类所在的 Jar 文件将被用于运行作业。job.setMapperClass(Map.class);和job.setReducerClass(Reduce.class)分别设置 Mapper 和 Reducer 类。这里,Map.class和Reduce.class分别指定了 Mapper 和 Reducer 的实现类。job.setOutputKeyClass(Text.class);和job.setOutputValueClass(IntWritable.class);:分别设置输出键和输出值的类型。这里,输出键类型是Text,输出值类型是IntWritable。job.setInputFormatClass(TextInputFormat.class);:用于指定 Mapper 如何读取输入数据。输入读取格式为TextInputFormat,映射器一次从输入文本文件中读取一行。job.setOutputFormatClass(TextOutputFormat.class);:设置输出格式。输出格式为TextOutputFormat。Path outputPath = new Path(args[1]):根据用户输入的参数,创建一个Path的对象,表示输出路径。FileInputFormat.addInputPath(job, new Path(args[0]));:将输入路径添加到作业配置中。
源代码 WordCount.java
package co.edureka.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class WordCount{
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable x: values)
{
sum += x.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//deleting the output path automatically from hdfs so that we don't have to delete it explicitly
outputPath.getFileSystem(conf).delete(outputPath, true);
//exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
说明:
- 在 Hadoop MapReduce 中,Mapper 和 Reducer 类是由 Hadoop 框架实例化和调用的,而不是由用户代码直接调用的。框架会根据用户在作业配置中指定的 Mapper 类 和Reducer 类来创建相应的实例,并将数据传递给它们进行处理。
- 本例中,通过
job.setMapperClass(Map.class)和job.setReducerClass(Reduce.class)分别设置了 Mapper 类和 Reducer 类。这告诉 Hadoop 框架,在运行作业时应该使用哪些类来执行 Map 和 Reduce 阶段的任务。
- 本例中,通过
outputPath.getFileSystem(conf).delete(outputPath, true);:如果输出路径存在文件则删除,以防止作业运行时出现输出路径已存在的错误。System.exit(job.waitForCompletion(ture)? 0 : 1);:提交作用并等待其完成。如果作业成功完成,则退出程序并返回状态码0; 如果作业失败或发生异常,则退出程序并返回状态码1。
MapReduce 任务执行
- Java 编译器编译源码:
[root@hadoop01 MapRedFiles]# javac -d /root/Documents/MapRedFiles/classes WordCount.java
-d参数指定类文件生成目录。
- 使用 JAR 工具打包成 JAR 文件:
[root@hadoop01 MapRedFiles]# jar cf WordCount.jar -C /root/Documents/MapRedFiles/classes .
HDFS 上存储文件,MapReduce 运行任务,确保各个节点成功启动。参考[[HDFS 集群部署# 启动节点]]
- 将本地
input.txt复制到 HDFS 文件系统中:
[root@hadoop01 MapRedFiles]# hdfs dfs -put -f input.txt /
- 使用
hadoop jar命令运行程序:
在Hadoop中执行MapReduce任务的基本命令格式:
hadoop jar <JAR文件路径> <主类名> [其他参数]
[root@hadoop01 MapRedFiles]# hadoop jar WordCount.jar co.edureka.mapreduce.WordCount /input.txt /output
说明:这是运行一个名为 WordCount 的 MapReduce 程序。
hadoop jar:是运行 Hadoop Job 的命令,后面跟 jar 文件的路径。co.edureka.mapreduce.WordCount:表示指定的主类,即包含main方法的类,且是完全限定名。本例中,在WordCount.jar中包含了WordCount类,并且它是你的 MapReduce 程序的入口点。/input.txt:指定 HDFS 中的输入路径。Hadoop 会将这个文件作为输入数据来运行 MapReduce 作业。/output:指定 HDFS 中的输出路径。本例中,输出结果将被写入到/output这个目录。- 参数传递:这个示例中,
/input.txt是传参数组args[]中 第一个传递参数 args[0],/output是 args[1];而co.edureka.mapreduce.WordCount并不是args数组中的元素,它只是告诉 Hadoop 框架 MapReduce 程序的入口主类。
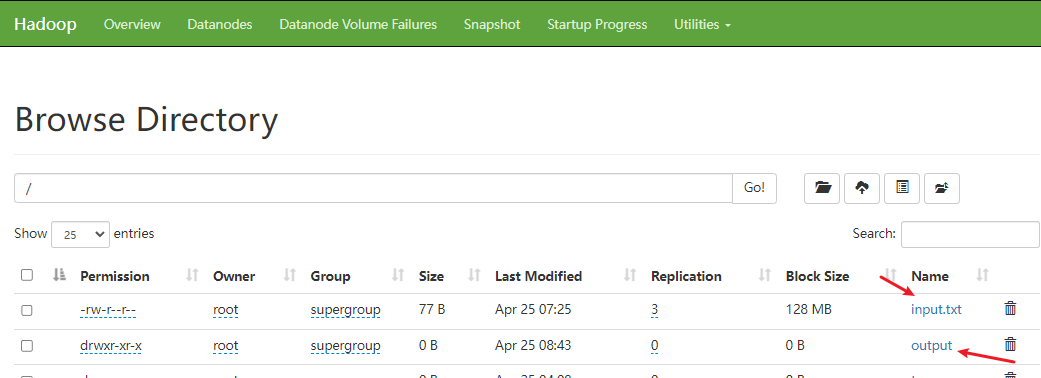
- MapReduce 运行任务生成
/output文件:
- 复制
/output文件到本地系统:
[root@hadoop01 MapRedFiles]# hdfs dfs -get /output .
- MapReduce 任务最终结果:
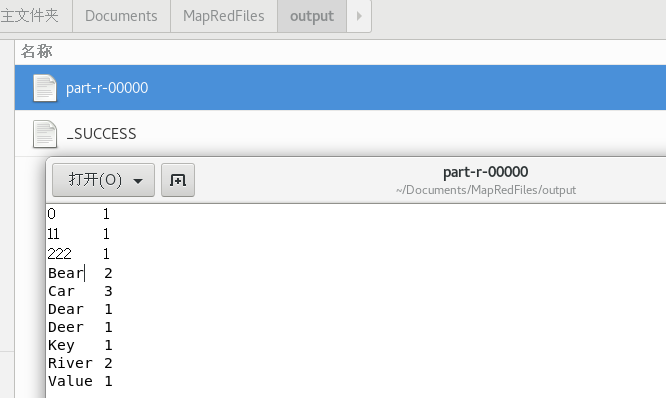
访问节点监视 MapReduce 任务
ResourceManager 访问查询
浏览器访问 http://192.168.83.131:8088/cluster ,查看资源调配并监视程序执行 :
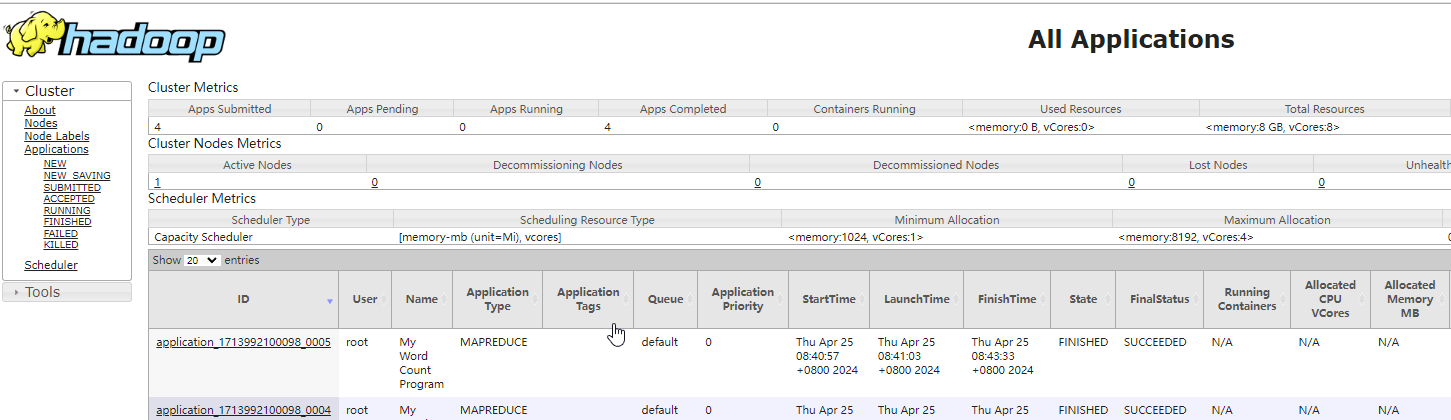
MapReduce 作业记录查询
浏览器访问 http://192.168.83.133:19888/jobhistory ,检查 JobHistory:

案例学习
使用 Hadoop 的 MapReduce 进行 KMeans 集群
K-Means 算法之手动选择 K 值
源代码:
package co.edureka.mapreduce;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class KMeans {
public static String OUT = "outfile";
public static String IN = "inputlarger";
public static String CENTROID_FILE_NAME = "/centroid.txt";
// 在Hadoop中,生成的路径文件形如 `part-r-00000` 是由Hadoop的输出格式决定的。
public static String OUTPUT_FILE_NAME = "/part-r-00000";
public static String DATA_FILE_NAME = "/data.txt";
public static String JOB_NAME = "KMeans";
public static String SPLITTER = "\t";
public static List<Double> mCenters = new ArrayList<Double>();
public static class Map extends Mapper<LongWritable, Text, DoubleWritable, DoubleWritable> {
@Override
public void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
URI[] cacheFilesURIs = context.getCacheFiles();
Path[] cacheFiles = new Path[cacheFilesURIs.length];
for (int i = 0; i < cacheFilesURIs.length; i++) {
cacheFiles[i] = new Path(cacheFilesURIs[i].toString());
}
if (cacheFiles != null && cacheFiles.length > 0) {
String line;
mCenters.clear();
FileSystem fs = FileSystem.get(conf);
try (BufferedReader cacheReader = new BufferedReader(new InputStreamReader(fs.open(cacheFiles[0])))) {
while ((line = cacheReader.readLine()) != null) {
String[] temp = line.split(SPLITTER);
mCenters.add(Double.parseDouble(temp[0]));
}
}
}
}
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
context.write(new DoubleWritable(nearest_center), new DoubleWritable(point));
}
}
public static class Reduce extends Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterable<DoubleWritable> values, Context context)
throws IOException, InterruptedException {
double newCenter;
double sum = 0;
int no_elements = 0;
StringBuilder points = new StringBuilder();
for (DoubleWritable value : values) {
double d = value.get();
points.append(" ").append(Double.toString(d));
sum += d;
++no_elements;
}
newCenter = sum / no_elements;
context.write(new DoubleWritable(newCenter), new Text(points.toString()));
}
}
// configureJob() 设置 MapReduce 作业
public static void configureJob(Job job, String inputPath, String outputPath, String cacheFilePath)
throws IOException {
job.setJobName(JOB_NAME);
job.setJarByClass(KMeans.class);
job.setMapOutputKeyClass(DoubleWritable.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(DoubleWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.setInputPaths(job, new Path(inputPath + DATA_FILE_NAME));
TextOutputFormat.setOutputPath(job, new Path(outputPath));
if (cacheFilePath != null && !cacheFilePath.isEmpty()) {
job.addCacheFile(new Path(cacheFilePath).toUri());
}
}
public static void run(String[] args) throws Exception {
String input = args[0];
String output = args[1];
String cacheFilePath = args.length > 2 ? args[2] : null;
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (!isdone) {
Job job = Job.getInstance(new Configuration());
if (iteration == 0) {
configureJob(job, input, output, input + CENTROID_FILE_NAME);
} else {
configureJob(job, input, output, again_input + OUTPUT_FILE_NAME);
}
job.waitForCompletion(true);
Path ofile = new Path(output + OUTPUT_FILE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
try (BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)))) {
List<Double> centers_next = new ArrayList<Double>();
String line;
while ((line = br.readLine()) != null) {
String[] sp = line.split(SPLITTER);
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
}
String prev = iteration == 0 ? input + CENTROID_FILE_NAME : again_input + OUTPUT_FILE_NAME;
Path prevfile = new Path(prev);
try (BufferedReader br1 = new BufferedReader(new InputStreamReader(fs.open(prevfile)))) {
List<Double> centers_prev = new ArrayList<Double>();
String l;
while ((l = br1.readLine()) != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
}
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}
public static void main(String[] args) throws Exception {
run(args);
}
}
解读:
- 在Hadoop中,生成的路径形如
part-r-00000是由Hadoop的输出格式决定的。在默认情况下,Hadoop会将输出文件分成多个分区,并使用类似part-r-00000这样的文件名来标识每个分区。 data.txt是数据预处理文件;centroid.txt自定义初始质心文件。
编译源码及环境准备:
javac -d /root/Documents/MapRedFiles/K-MEANS/classes ./KMeans.java
jar cf KMeans.jar -C /root/Documents/MapRedFiles/K-MEANS/classes .
hdfs dfs -mkdir -p /KMeans
hdfs dfs -put -f data.txt /KMeans
hdfs dfs -put -f centroid.txt /KMeans
[root@hadoop01 K-MEANS]# hadoop jar ./KMeans.jar co.edureka.mapreduce.KMeans /KMeans /KMeans/output /KMeans
./output运行命令时自动创建。