HDFS 集群部署
HDFS 简介
HDFS (Hadoop Distributed File System) 是一种基于 Java 的分布式文件系统,允许你跨 Hadoop 集群中的多个节点存储数据,专为大规模数据存储和高吞吐量数据访问而设计。
HDFS 优点是分布式存储,由于数据是跨机器划分存储的,利用分布式并行计算。
当你将数据存储在 HDFS 上时,它会在内部将给定数据划分为数据块,并以分布式方式存储在 HDFS集群中。关于哪个数据块位于哪个数据节点上的信息记录在元数据中。
HDFS有个特点,不同于传统方式,我们将处理单元移动到数据所在的节点,而不是将节点上的数据移动到处理单元计算处理。
HDFS 架构
HDFS 主/从拓扑
HDFS 架构遵循 主/从架构,集群由单个 NameNode(主节点)和多个DataNode(从节点)组成。HDFS 可以部署在支持 Java 的各种机器上。虽然可以在一台机器上运行多个 DataNode,但在实际应用中,这些 DataNode 分布在不同的机器上。
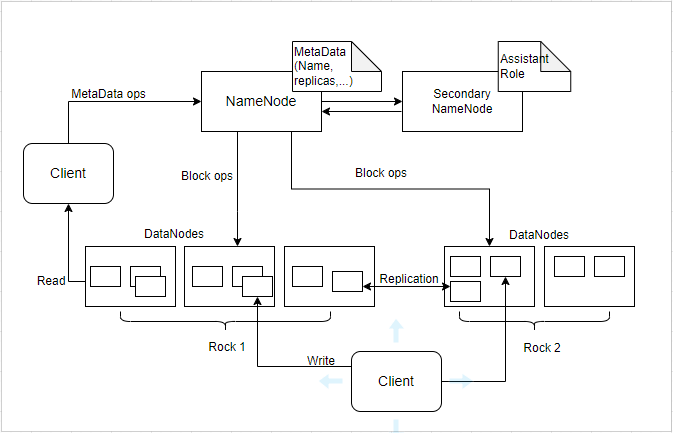
NameNode
NameNode 是 HDFS 架构中的主节点,用于维护和管理 DataNode (从节点)上存在的块。它管理文件系统命名空间并控制客户端对文件的访问。HDFS 架构的构建方式使得用户数据永远不会驻留在 NameNode 上,数据仅驻留在 DataNode 上。简而言之,NameNode 管理元数据,DataNode 负责存储数据。
NameNode 功能:
- 它是维护和管理 DataNode(从节点)主守护进程。
- 它记录了集群中存储的所有文件的元数据。如文件大小、权限、层级结构及存储块的位置等等。与元数据相关的文件有两个:
- FsImage:它包含 NameNode 启动以来文件系统名称空间的完整状态。
- EditLogs:它包含相对于最新 FsImage 对文件系统所做的所有最新修改。
- 它记录文件系统元数据发生的每个更改。如 HDFS 中删除一个文件,NameNode 会立即将其记录在 EditLog 中。
- 它定期接收来自集群中所有 DataNode 的心跳和块报告,以确保 DataNode 处于活动状态。
- NameNode 还负责处理所有块的复制因子(replication)。
- 如果 DataNode 节点发生故障,NameNode 会为新副本选择新的 DataNode 节点,平衡磁盘使用情况并管理与 DataNode 的通信流量。
DataNode
DataNode 是 HDFS 中的从节点。与 NameNode 不同,DataNode 是一个存储数据的块服务器。
DataNode 功能:
- 它运行的是从属守护程序或进程。
- 实际数据存储在 DataNode 上。
- 执行来自分布式文件系统客户端的低级读取和写入请求。
- 它们定期向 NameNode 发送心跳来报告 HDFS 的整体健康状态,默认情况下,设置频率为 3 秒。
Secondary NameNode
Secondary NameNode 是除了以上两种守护进程之外的,第三种守护进程,辅助名称节点(也可称次命名节点)。辅助 NameNode 作为辅助守护进程与 主 NameNode 同时工作。
它类似命名节点的 “秘书”,因为它并不能代替命名节点的工作,无论命名节点是否有能力继续工作。
它主要负责分摊命名节点的压力、备份命名节点的状态并执行一些管理工作,如果命名节点坏掉,它也可以提供备份数据以恢复命名节点。它也可以有多个。

Secondary NameNode 的功能:
- Secondary NameNode 不断地从 NameNode 的 RAM 中读取所有文件系统和元数据,并将其写入磁盘或文件系统。
- 负责将 EditLogs 与来自 NameNode 的 FsImage 组合起来。它定期从 NameNode 下载 EditLogs 并应用于 FsImage。新的 FsImage 被复制到 NameNode,下次 NameNode 启动时使用该 FsImage。
Secondary NameNode 在 HDFS 中执行定期检查。因此,也称为 CheckPointNode。
HDFS 读/写架构
HDFS 遵循“一次写入、多次读取”的哲学。文件一旦写入 HDFS 并关闭,就不能再被修改或更新,它简化了数据一致性和分布式处理的管理。
尽管不能修改文件,HDFS 允许附加(append)数据到已存在的文件中,但操作有限,并且附加数据只能进行在文件末尾,而不能随机修改文件内容。
HDFS 2.x 高可用集群架构
Hadoop 安装配置
Hadoop 是以 HDFS 作为底层存储系统,用于在分布式环境下存储数据。
Hadoop 有两种安装方式,即单节点和多节点。
单节点集群意味着只有一个 DataNode 在一台机器上运行并设置所有 NameNode、DataNode、ResourceManager 和 NodeManager。一般用于学习和测试目的。
而多节点集群,有多个 DataNode 在运行,并且每个 DataNode 运行在不同的机器上。多节点集群在组织中实际用于分析大数据。
集群模式
本例使用全分布式运行 Hadoop 集群。关于 [[Hadoop 集群架构描述]]。
节点分布说明:
| 主机名 | 节点类型 | 节点说明 |
|---|---|---|
| hadoop01 | NameNode [NodeManager] | NameNode 作为 HDFS 主节点,负责管理文件系统命名空间并调节客户端对文件的访问。 |
| hadoop02 | ResourceManager / [NodeManager] | ResourceManager 负责管理集群资源和调度任务。NodeManager 负责启动和监视。 |
| hadoop03 | DataNode / [NodeManager] | 充当工作节点,负责在 HDFS 中存储实际数据。 |
| hadoop04 | ProxyServer / MapReduce [NodeManager] | 其他服务节点(例如 Web 应用程序代理服务器和 MapReduce 作业历史记录服务器) |
检查多节点主机的 IP 地址(使用 ifconfig 命令)。
使用 hostnamectl 命令来设置新的主机名。如:
hostnamectl set-hostname hadoop01
在主机文件 /etc/hosts 中添加主节点和数据节点及其各自的 IP 地址映射关系。
192.168.83.130 hadoop01
192.168.83.131 hadoop02
192.168.83.132 hadoop03
192.168.83.133 hadoop04
注意:暂时禁用防火墙限制。所有主机使用同一套配置参数。
先决条件
准备环境:
- 虚拟机环境 VMware Player 或 VMware Workstation Pro
- Linux 操作系统 CentOS 7
- CentOS 7 已默认安装 OpenJDK 1.8
- SSH 服务
- hadoop-3.3.6
如果 jps 命令不可用,安装 JDK 的开发工具包。
yum update
yum install java-1.8.0-openjdk-devel # 如果使用的是 OpenJDK 1.8
说明:jps 命令用于列出 Java 虚拟机 (JVM) 上正在运行的 Java 进程。在 Hadoop 集群中,每个节点上都会运行多个 Java 进程来执行不同的 Hadoop 组件。使用 jps 命令可以检查 Hadoop 节点进程是否成功启动。
配置 SSH 可信访问
如果要使用可选的启动和停止脚本,可以安装 SSH。,并且在 Hadoop 集群中的每个节点上运行 sshd 服务进程,以便主节点通过 SSH 远程启动和管理从节点的 Hadoop 守护进程 。此外,建议还安装 pdsh 以更好地管理 SSH 资源。
- 启动 sshd 服务;若没有,自行安装。
$ systemctl start sshd
- 在主节点上创建 SSH 密钥。
$ ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
说明:
- 该命令会生成一个 RSA 密钥对,包括一个私钥和一个公钥。私钥用于对数据进行签名或解密,而公钥用于验证签名或加密数据。
-P "":实现 SSH 免密登录。-f ~/.ssh/id_rsa:生成的授权密钥保存至id_rsa文件。
- 将生成的 SSH 密钥复制到主节点的授权密钥中。
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
- 将主节点的 SSH 密钥复制到从节点的授权密钥。
$ ssh-copy-id -i ~/.ssh/id_rsa.pub user@remotehost
- 验证 SSH 连接远程主机。
$ ssh user@remotehost
示例:
[root@hadoop .ssh]# ssh root@192.168.83.130
Last login: Sun Apr 21 21:08:09 2024
[root@hadoop02 ~]#
安装 Hadoop
- 下载 Hadoop(可执行的二进制发布包)
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.6/hadoop-3.3.6.tar.gz
- 提取 Hadoop tar 文件到指定目录
/opt
tar -zxf hadoop-3.3.6.tar.gz -C /opt
- 编辑
/etc/profile或用户根目录.bashrc文件
vim /etc/profile
设置 Hadoop 环境变量内容: ^bc49c1
# 配置 Hadoop 系统环境变量
export HADOOP_HOME=/opt/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.libray.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/share/hadoop/client/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/yarn/*
说明:
$HADOOP_OPTS环境变量属性值告诉 Java 虚拟机在加载本机库时应该搜索的 Hadoop 本地库路径。
- 验证 Hadoop 安装
hadoop version
编辑配置文件
编辑 Hadoop 配置文件。Hadoop 所有配置都位于 etc/hadoop 目录中,在给定配置文件中配置重要参数。
core-site.xml 文件
core-site.xml 文件通知 Hadoop 守护进程 NameNode 在集群中运行的位置。它包含 Hadoop 核心的配置设置。例如 HDFS 和 MapReduce 常见的 I/O 设置。
core-site.xml 核心配置:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置 NameNode URI。默认使用的端口号9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 配置 NameNode 的 RPC 地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!--用于指定SequenceFiles中使用的读/写缓冲区的大小。-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--定义了 Hadoop 临时目录的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/local/hadoop/tmp</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
说明:集群节点通信地址,一般可以根据地址格式使用主机名或 IP 地址。集群内主机在 Web 页面访问管理节点可以使用主机名或 IP 地址;集群外主机在 Web 页面访问集群节点只能使用 IP 地址。
hdfs-site.xml 文件
hdfs-site.xml 文件包含 HDFS 守护进程(即 NameNode、DataNode、Secondary NameNode)的配置设置。还包含 HDFS 的复制因子、块大小和权限检查等。
hdfs-site.xml 核心配置:
<configuration>
<!-- 指定 NameNode 存储元数据的目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>
/var/local/hadoop/data/namenode/first,
/var/local/hadoop/data/namenode/second
</value>
</property>
<!-- 指定 DataNode 存储数据块的目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>
/var/local/hadoop/data/datanode/first,
/var/local/hadoop/data/datanode/second
</value>
</property>
<!-- 指定 HDFS 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 配置 NameNode 的 RPC 地址。默认端口 8020 -->
<property>
<name>dfs.namenode.rpc-address</name>
<value>hadoop01:8020</value>
</property>
<!-- 配置 DataNode 的地址 -->
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50010</value>
</property>
<!-- 配置 DataNode 的 HTTP 地址 -->
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<!-- 配置 DataNode 的 IPC 地址 -->
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<!-- 启用 HDFS 权限 -->
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
</configuration>
说明:通常使用 0.0.0.0 表示监听所有网络接口上的连接。这意味着 DataNode 将接受来自任何网络接口的连接。
mapred-site.xml 文件
mapred-site.xml 文件包含 MapReduce 应用程序的配置设置,例如可以并行运行的 JVM 数量、映射器和减速器进程的大小、进程可用的 CPU 核心等。
mapred-site.xml 核心配置:
<configuration>
<!-- MapReduce 应用程序相关参数 -->
<property>
<!-- 指定 MapReduce 框架类型。在 YARN 上运行 MapReduce 作业 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!-- 指定 MapReduce 应用程序的类路径。-->
<!-- 默认包含安装目录 Hadoop 分发包中的相关 JAR 文件 -->
<name>mapreduce.application.classpath</name>
<value>
$HADOOP_HOME/share/hadoop/client/*,
$HADOOP_HOME/share/hadoop/common/*,
$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,
$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,
$HADOOP_HOME/share/hadoop/tools/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,
$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>
<!-- MapReduce JobHistory Server 相关参数 -->
<property>
<!-- 指定 MapReduce JobHistory Server 监听的地址和端口 -->
<name>mapreduce.jobhistory.address</name>
<value>hadoop04:10020</value>
</property>
<property>
<!-- 指定 MapReduce JobHistory Server Web 页面访问的地址和端口 -->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop04:19888</value>
</property>
<!-- MapReduce 作业历史记录的中间存储目录 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/tmp/mapred/history/intermediate</value>
</property>
<!-- MapReduce 作业历史记录的最终存储目录 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/tmp/mapred/history/done</value>
</property>
</configuration>
yarn-site.xml 文件
yarn-site.xml 文件包含 ResourceManager 和 NodeManager 的配置设置,如应用程序内存管理大小、程序和算法所需的操作等。
yarn-site.xml 核心配置:
<configuration>
<!-- ResourceManager 的主机名或 IP 地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- ResourceManager 的地址和端口,用于与客户端进行通信 -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop02:8032</value>
</property>
<!-- ResourceManager 的调度器地址和端口。默认端口是 8030 -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop02:8030</value>
</property>
<!-- ResourceManager 提供 Web 页面的地址和端口。默认端口是 8088 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop02:8088</value>
</property>
<!-- NodeManager 存储本地数据的目录 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/var/local/hadoop/yarn.nodemanager.local</value>
</property>
<!-- NodeManager 存储日志文件的目录 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/var/local/hadoop/yarn.nodemanager.log</value>
</property>
<!-- 运行在 NodeManager 的辅助服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hadoop-env.sh 文件
etc/hadoop/hadoop-env.sh 文件用于设置 Hadoop 环境变量和其他属性。如 Java 主路径等。
# 设置 Java 安装根目录
export JAVA_HOME=/usr
说明:检查 Java 安装可执行文件的根目录:which java,例如:
# which java
/usr/bin/java
指定运行 HDFS 守护进程的用户环境变量配置:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
注意:使用 root 用户运行 Hadoop 服务通常不是最佳实践,因为可能会带来安全性问题。在生产环境中配置专门的用户来运行 Hadoop 进程。
yarn-env.sh 文件
etc/hadoop/yarn-env.sh 文件是用来配置 YARN 环境的脚本文件。它允许您设置环境变量和其他属性,以控制 YARN 的行为。
指定 ResourceManager 和 NodeManager 进程的用户环境变量:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
workers 文件
etc/hadoop/workers 文件用于列出 Hadoop 集群中作为工作节点的机器的主机名或 IP 地址。每行一个主机名或 IP 地址。
localhost
hadoop01
hadoop02
hadoop03
hadoop04
说明:在所有节点复制 Hadoop 配置文件。
操作 Hadoop 集群
初始化 HDFS
通过 NameNode 初始化 HDFS(仅在主节点上),进入 Hadoop 主目录并格式化 NameNode。
hdfs namenode -format
注意:该命令仅在第一次执行。切勿后续重新格式化 Hadoop 文件系统,否则将丢失 HDFS 存储的所有数据。
启动节点
方式一:
在指定节点上以 hdfs 用户的身份启动 HDFS NameNode 守护进程:
hdfs --daemon start namenode
在指定节点上以 hdfs 用户的身份启动 DataNode 守护进程:
hdfs --daemon start datanode
在指定节点以 yarn 用户的身份启动 NodeManager 守护进程:
yarn --daemon start nodemanager
在指定节点以 yarn 用户的身份启动 ResourceManager 守护进程:
yarn --daemon start resourcemanager
若启动独立的 WebAppProxy 服务器。作为 yarn 在 WebAppProxy 服务器上运行。如果将多个服务器用于负载平衡,则应在每个服务器上运行它。
yarn --daemon start proxyserver
参考 Web 应用程序代理
在指定节点上启动 MapReduce History Server:
mapred --daemon start historyserver
方式二:
若配置了 SSH 免密远程登录,可以使用脚本启动停止相关进程。
启动所有守护进程(在主节点上):
$HADOOP_HOME/sbin/start-all.sh
示例:
[root@hadoop01 ~]# $HADOOP_HOME/sbin/start-all.sh
Starting namenodes on [hadoop01]
上一次登录:五 4月 26 18:37:26 CST 2024pts/0 上
Starting datanodes
上一次登录:五 4月 26 18:40:00 CST 2024pts/0 上
Starting secondary namenodes [hadoop01]
上一次登录:五 4月 26 18:40:02 CST 2024pts/0 上
Starting resourcemanager
上一次登录:五 4月 26 18:40:08 CST 2024pts/0 上
Starting nodemanagers
上一次登录:五 4月 26 18:40:15 CST 2024pts/0 上
启动所有 HDFS 进程:
$HADOOP_HOME/sbin/start-dfs.sh
启动所有 YARN 进程:
$HADOOP_HOME/sbin/start-yarn.sh
说明:通常在 Hadoop 集群的主节点上执行。主节点通常是 NameNode 和 ResourceManager 所在的节点。这两个命令用于启动 Hadoop 分布式文件系统(HDFS)和资源管理器(YARN)服务,这是 Hadoop 集群的核心组件。
检查节点状态
检查已启用的守护进程:
jps
关闭节点
方式一:
在指定的 ResourceManager 节点上停止 resourcemanager 进程:
yarn --daemon stop resourcemanager
说明:在节点上停止服务进程,将命令中的 start 替换成 stop。
在指定节点上停止 historyserver 进程:
mapred --daemon stop historyserver
方式二:
使用如下程序脚本停止所有进程:
$HADOOP_HOME/sbin/stop-all.sh
示例:
[root@hadoop01 ~]# $HADOOP_HOME/sbin/stop-all.sh
Stopping namenodes on [hadoop01]
上一次登录:五 4月 26 18:40:17 CST 2024pts/0 上
Stopping datanodes
上一次登录:五 4月 26 18:42:09 CST 2024pts/0 上
Stopping secondary namenodes [hadoop01]
上一次登录:五 4月 26 18:42:10 CST 2024pts/0 上
Stopping nodemanagers
上一次登录:五 4月 26 18:42:13 CST 2024pts/0 上
hadoop01: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
hadoop04: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
hadoop02: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
hadoop03: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
Stopping resourcemanager
上一次登录:五 4月 26 18:42:16 CST 2024pts/0 上
使用如下程序脚本停止所有 HDFS 进程:
$HADOOP_HOME/sbin/stop-hds.sh
使用如下程序脚本停止所有 YARN 进程:
$HADOOP_HOME/sbin/stop-yarn.sh
Web 界面访问
以下是 Hadoop 集群中常见守护进程的 Web 界面及其默认端口配置。每个守护进程都有一个 Web 界面用于监控和管理集群的状态。
| Daemon | Web Interface | Notes |
|---|---|---|
| NameNode | http://nn_host:port/ | Default HTTP port is 9870. |
| ResourceManager | http://rm_host:port/ | Default HTTP port is 8088. |
| MapReduce JobHistory Server | http://jhs_host:port/ | Default HTTP port is 19888. |
一旦 Hadoop 集群启动并运行,可以检查组件的 Web-UI。
NameNode 节点访问
浏览器访问 http://192.168.83.130:9870/dfshealth.html
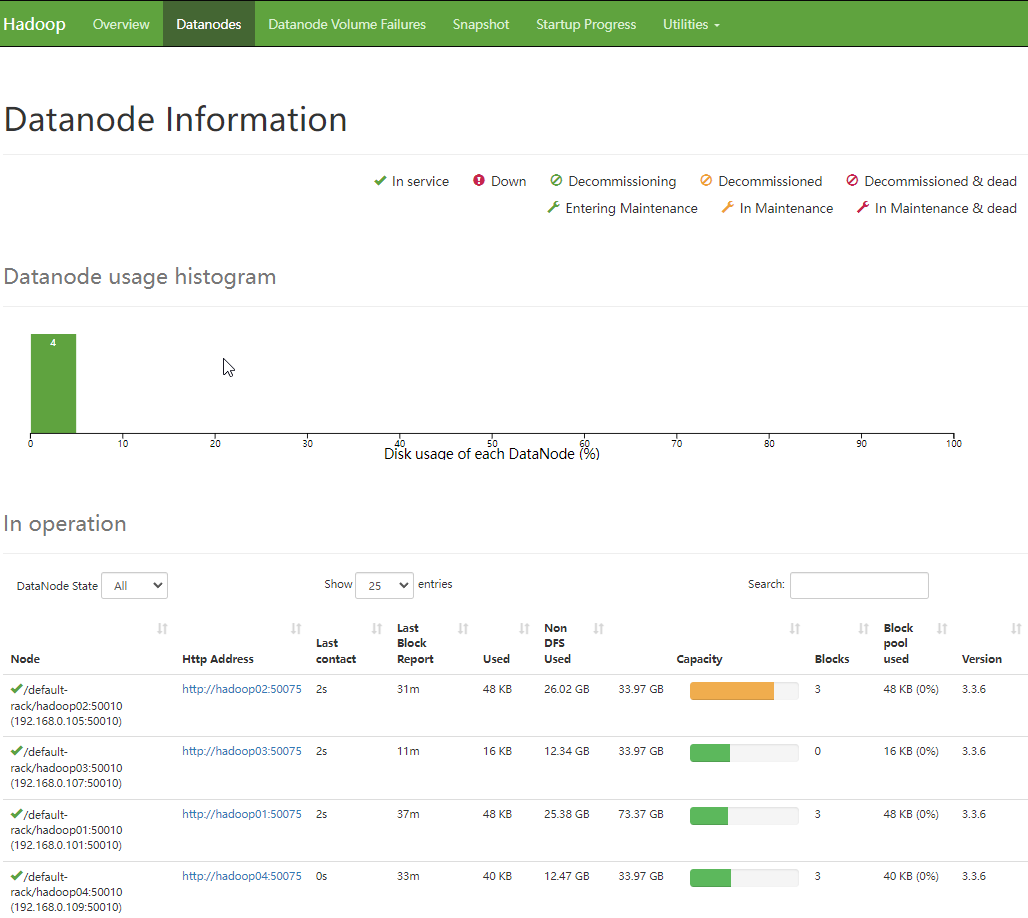
在 NameNode 界面,可以查看活动节点的数量。

DataNode 节点信息显示页面:
浏览 HDFS 存储情况:
ResourceManager 节点访问
[[MapReduce 框架基础#ResourceManager 访问查询|ResourceManager 节点访问]]
MapReduce JobHistory Server 节点访问
[[MapReduce 框架基础#MapReduce 作业记录查询|MapReduce JobHistory Server 节点访问]]
参考
问题
问题1. 启动集群节点报错:
hdfs --daemon start namenode
ERROR: Cannot set priority of namenode process 5081
解决:
- 因为刚更新了配置,尝试 hdfs 格式化,发现节点配置文件格式有错误,定位修改即可。
问题2. 数据节点 datanode 启动后又自动退出,检查日志如 hadoop-root-datanode-hadoop01.log
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering>
解决:可能的原因,NameNode 和 DataNode 集群 ID 不匹配:
hdfs-site.xml中字段dfs.namenode.name.dir指定了 NameNode 节点存储数据块的目录;dfs.datanode.name.dir指定了 DataNode 节点存储数据块的目录。- 确保
dfs.datanode.name.dir/current/VERSION中的clusterID字段与$dfs.namenode.name.dir/current/VERSION中的clusterID字段保持一致。 - 或完全格式化 NameNode 节点,注意格式化 HDFS 系统存储的数据会全部丢失:
hdfs namenode -format
问题3. 数据节点 datanode 启动失败,检查日志:
2024-04-22 08:17:59,220 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/var/local/hadoop/data/datanode/first
org.apache.hadoop.hdfs.server.common.IncorrectVersionException: Unexpected version of storage directory /var/local/hadoop/data/datanode/first. Reported: -66. Expecting = -57.
解决:尝试删除 DataNode 数据库目录,如日志中的 /var/local/hadoop/data/datanode/**first** ,然后重新启动 DataNode 节点。
问题4. historyserver 服务启动失败,检查日志 logs/hadoop-root-historyserver-hadoop.log
Caused by: java.net.BindException: Port in use: hadoop4:19888
at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1369)
at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1391)
at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1454)
at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1300)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:472)
... 9 more
Caused by: java.io.IOException: Failed to bind to hadoop4:19888
at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:349)
at org.eclipse.jetty.server.ServerConnector.open(ServerConnector.java:310)
at org.apache.hadoop.http.HttpServer2.bindListener(HttpServer2.java:1356)
at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1387)
... 12 more
Caused by: java.net.SocketException: Unresolved address
at sun.nio.ch.Net.translateToSocketException(Net.java:134)
at sun.nio.ch.Net.translateException(Net.java:160)
at sun.nio.ch.Net.translateException(Net.java:166)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:87)
at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:344)
... 15 more
Caused by: java.nio.channels.UnresolvedAddressException
at sun.nio.ch.Net.checkAddress(Net.java:104)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:217)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:85)
... 16 more
2024-04-25 05:11:27,643 INFO org.apache.hadoop.service.AbstractService: Service org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer failed in state STARTED
org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server
分析解决:从日志看,绑定端口失败,首先,netstat 命令检查端口是否占用,若未占用,检查 mapred-site.xml 中关于端口的配置项是否正确。