Apache Hive 架构基础
什么是 Hive ?
Apache Hive 是_Hadoop 生态系统 中的一个数据仓库工具,它提供类似 SQL 的语言来查询和分析大数据。
Apache Hive 是一个构建在 Hadoop 之上 的数据仓库系统,用于分析结构化和半结构化数据。 Hive 抽象了 Hadoop MapReduce 的复杂性。它提供了一种将结构投影到数据上并执行用 HQL(Hive 查询语言) 编写的类似于 SQL 语句的查询机制。这些查询或 HQL 由 Hive 编译器转换为 MapReduce 作业。因此,无需担心编写复杂的 MapReduce 程序来使用 Hadoop 框架处理数据。
Hive 针对的是熟悉 SQL 的用户。Apache Hive 支持数据定义语言(DDL)、数据操作语言(DML)和用户自定义函数(UDF)。
Apache Hive 的优点:
- 它消除了编写复杂 MapReduce 程序的需要,提供类似于 SQL 的 Hive 查询语言,易于学习。
- 由于 Hive 运行在 Hadoop 之上,因此具有可扩展、可伸缩,以应对不断增长的数据量和种类,而不影响系统性能。
- Hive Thrift 服务器支持用 Java、PHP、Python、C++ 或 Ruby 编写的任何客户端应用程序(使用这些嵌入 SQL 的客户端语言来访问数据库)。
- 由于 Hive 元数据信息存储在关系型数据库管理系统(RDBMS),大大减少了查询执行期间执行语义检查的时间。
Hive 和 SQL 的区别:
Hive 是看起来类似于具有 SQL 访问权限的传统数据库。然而,由于 Hive 基于 Hadoop 和 MapReduce 操作,因此存在几个关键区别:
- 由于 Hadoop 旨在用于长时间顺序扫描,而 Hive 基于 Hadoop,因此期望查询可能具有非常高的延迟。这意味着 Hive 不适合那些需要快速响应的应用程序。
- Hive 是基于读取的,因此不适合通常涉及高比例写入操作的事务处理。
Apache Hive 应用领域:
Apache Hive 利用了 SQL 数据库系统和 Hadoop MapReduce 框架,主要用于数据仓库,可以在其中执行不需要处理的分析和数据挖掘。应用领域有:
- 数据仓库
- 临时分析
将 Hive 与其他工具结合起来,以便在许多其他领域中使用它。例如,Tableau 与 Apache Hive 一起可用于数据可视化,Tez 与 Hive 集成将为您提供实时处理功能等。
Hive 架构及其组件
如下描述了 Hive 结构以及查询提交到 Hive 并最终使用 MapReduce 框架进行处理的流程:
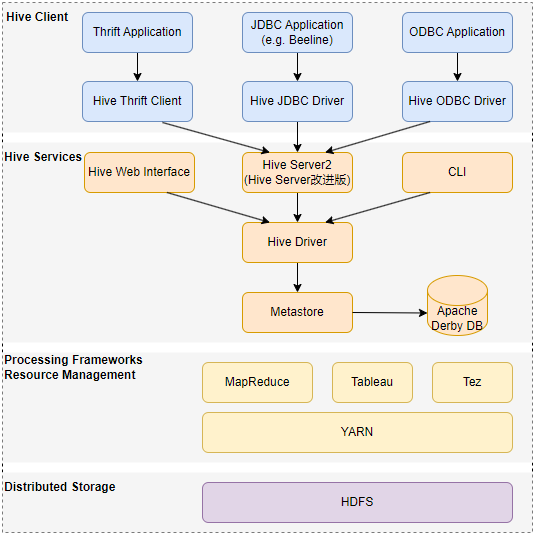
说明:
- Hive 客户端:Hive 支持使用 Thrift、JDBC 和 ODBC 驱动程序以多种语言编程的应用程序。
- Hive 服务器:Apache Hive 提供各种服务(例如 CLI、Web 界面等)来执行查询。
- 处理框架和资源管理:在内部,Hive 使用 Hadoop MapReduce 框架作为事实上的引擎来执行查询。
- 分布式存储:Hive 是安装在 Hadoop 之上的,它使用底层 HDFS 进行分布式存储。
Hive 客户端
Apache Hive 支持不同类型的客户端应用程序在 Hive 上执行查询。这些客户分为三类:
- Thrift 客户端:由于 Hive 服务器基于 Apache Thrift,因此,它可以服务所有支持 Thrift 的编写语言的请求。
- JDBC 客户端:Hive 允许 Java 应用程序使用 JDBC 驱动程序连接到它,JDBC 驱动程序是在类
org.apache.hadoop.hive.jdbc.HiveDriver中定义的。 - ODBC 客户端:Hive ODBC 驱动程序允许支持 ODBC 协议的应用程序连接到 Hive。与 JDBC 驱动程序一样,ODBC 驱动程序使用 Thrift 与 Hive 服务器进行通信。
Hive 服务
Hive 提供了许多服务,如下:
- Hive CLI(命令行界面):这是 Hive 提供的默认 shell,在其中可以直接运行 Hive 查询和命令以管理查询 HDFS 上的数据。
- Apache Hive Web 界面:Hive 还提供基于 Web 的 GUI,用于执行 Hive 查询和命令。
- Hive Server:Hive 服务器基于 Apache Thrift 构建,因此也称为 Thrift Server,允许不同的客户端向 Hive 提交请求并检索最终结果。
- Apache Hive Driver:它负责接收客户端通过 CLI、Web 界面、Thrift、ODBC 或 JDBC 接口提交的查询。然后,驱动程序将查询传递给编译器,在编译器中借助元存储中存在的模式进行解析、类型检查和语义分析。然后,以 map-reduce 任务和 HDFS 任务的 DAG(有向无环图)的形式生成优化的逻辑计划。最后,执行引擎使用 Hadoop 按照任务的依赖顺序执行这些任务。(简言之:客户端查询-》驱动程序传递-》编译器解析-》优化逻辑生成任务-》执行任务)
- Metastore:将 Metastore 视为存储所有 Hive 元数据信息的中央存储库。Hive 元数据包括各种类型的信息,例如表结构和分区以及列、列类型、序列化器和反序列化器,这是对 HDFS 中存储的数据进行读/写操作所需的信息。元存储有两个基本单元组成:
- 提供对其他 Hive 服务的元存储访问的服务。
- 元数据的磁盘存储与 HDFS 存储分开。
元存储配置
Metastore 使用 RDBMS 和 DataNucleus(开源的对象关系映射框架) 存储元数据信息。DataNucleus 提供了一种抽象层,将 Java 程序中实现对象与关系型数据库进行映射,允许开发人员通过对象来操作数据库。选择 RDBMS 而不是 HDFS的原因是为了实现低延迟。
可以通过以下三种配置实现元存储:
嵌入式元存储
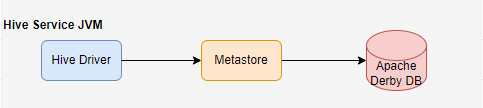
默认情况下,Metastore 服务和 Hive 服务使用嵌入式 Derby 数据库实例在同一 JVM 中运行,其中元数据存储在本地磁盘中。这种称之为嵌入式云存储。
这种配置场景下,一次只有一个用户可以连接到 Metastore 数据库。如果启动 Hive 驱动程序的第二个实例,将会出错。适合进行单元测试。
本地元存储
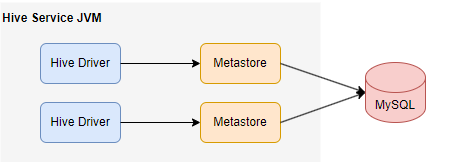
此配置允许我们拥有多个 Hive 会话,即多个用户可以同时使用 Metastore 数据库。这是通过使用任何兼容 JDBC 的数据库来实现的。
例如,MySQL 数据库作为 Hive 元存储服务。Hive 及其相关服务(如 Metastore )运行在 JVM 中,并通过 JDBC 连接到 MySQL 访问这些元数据。
因此,一般可以选择将 MySQL 服务器作为元存储数据库。
远程元存储
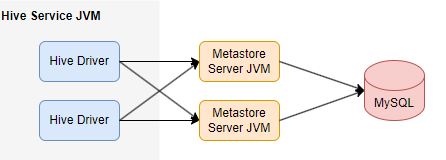
在远程元数据存储配置中,元存储服务运行在自己单独的 JVM 上,而不是在 Hive 服务 JVM 中,并通过 Thrift 网络 API 提供其他进程访问。在这种情况下,可以使用一个或多个元存储服务器来提高可用性。
无论元数据存储在本地还是远程数据库中,Hive 客户端(如 Hive CLI、Beeline 或者其他 Hive JDBC 客户端)都可以通过 Hive 服务来访问 Hive 元数据。
因此,当元数据存储在数据库中时,Hive 客户端无需直接连接到这个数据库。Hive 服务会代理所有的元数据操作,并将这些操作传递给远程数据库。这意味着,即使客户端不知道或没有 JDBC 登录凭据连接到元数据数据库,它仍然可以通过 Hive 服务来执行元数据操作。
数据模型
Hive 中的数据按粒度可以分为三种类型:
- Table
- Partition
- Bucket
表格
Hive 中的表与关系型数据库中的表相同。你可以对它们执行过滤、投影、连接和并集操作。
Hive 中有两种类型的表:托管表和外部表。
托管表
Hive 负责管理托管表的数据。将 HDFS 文件中的数据加载到 Hive 托管表中。
当从 HDFS 文件位置向 Hive 仓库目录发出 LOAD 命令时,就是在移动数据到 Hive 仓库目录中。然后,Hive 会为托管表创建元数据信息。
当对托管表发出 DROP 命令,该表及其元数据就会被删除。因此,被删除的托管表的数据不再存在于 HDFS 中的任何地方,你也无法通过任何方式检索到它。
命令格式:
创建表:
CREATE TABLE <table_name>(column1 data_type, column2 data_type);
加载数据:
LOAD DATA INPATH <HDFS_file_location> INTO table managed_table;
说明:在 HDFS中,仓库目录默认路径一般为 /user/hive/warehouse。 Hive 表的数据位于 warehouse_directory/table_name 。可以在 hive-site.xml 中的 hive.metastore.warehouse.dir 配置参数指定仓库目录的路径。
外部表
对于外部表,Hive 不负责管理数据。在这种情况下,当发送 LOAD 命令时,Hive 会将数据移动到其仓库目录中。然后,Hive 会为外部表创建元数据信息。此时,如果对外部表发送 DROP 命令,只有外部表的元数据信息会被删除,你仍然可以使用 HDFS 命令从仓库目录中重新获取该外部表的数据。
命令格式:
创建表:
CREATE EXTERNAL TABLE <table_name>(column1 data_type, column2 data_type) LOCATION '<table_hive_location>';
加载数据:
LOAD DATA INPATH '<HDFS_file_location>' INTO TABLE <table_name>;
分区
Hive 将表组织分区,以便根据列或分区键将同类数据分组。每个表可以有一个或多个分区键来标识特定分区。这样,我们就能更快地查询数据切片。
命令格式:
CREATE TABLE table_name (column1 data_type, column2 data_type) PARTITIONED (partition1 data_type, partition2 data_type,...);
注意:创建分区时请勿将现有列名指定为分区列。否则会有语义分析报错:Error in semantic analysis: Column repeated in partitioning columns
学生数据表分区示例:
若有一个学生表 student_details,学生信息包括 student_id、student_name、admission_time、department 等等。
现在,对 college_name 列进行分区,将属于特定学院的学生数据存储在一个分区中。从物理结构上讲,分区是表目录中的一个子目录。
假设 student_details 表有三个院系的数据:Engineering、Medicine、Science。每个学院的所有数据,都会存储在 Hive 表目录下的单独子目录中。
例如,将有关 Medicine 学院的所有学生数据存储在 /user/hive/warehouse/stduent_details/dept.=Medicine。因此,有关 Medicine 学生的查询只需查看 Medicine 分区中存在的数据即可。这使得分区非常有用,因为它仅扫描相关的分区数据而不是整个数据集进而减少查询延迟。
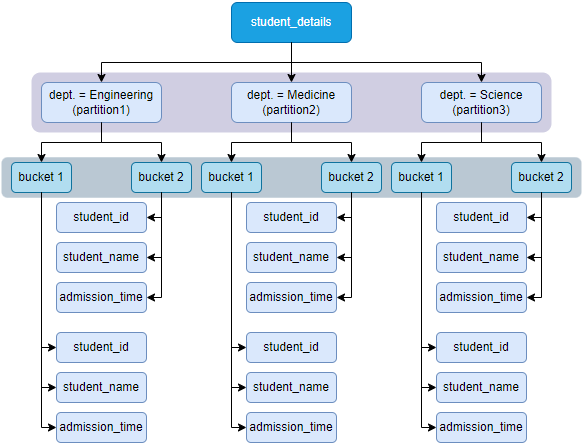
分桶
定义一个分区表,并通过分桶对数据进行存储,命令格式:
CREATE TABLE table_name PARTITIONED BY (partition1 data_type, partition2 data_type, ...) CLUSTERED BY (column_name1, column_name2, ...) SORTED BY (column_name [ASC | DESC], ...) INTO num_backets BUCKETS;
说明:
PARTITIONED BY (partition1 data_type, partition2 data_type, ...):指定表的分区键,将数据按照指定的分区键进行分区存储。CLUSTERED BY (column_name1, column_name2, ...):指定了表的桶化列,这些列的数据将被按行被分别存储到不同的桶中。SORTED BY (column_name [ASC | DESC], ...):指定在每个桶内如何排序数据,可以选择升序或降序,并且可以指定一个或多个列名。INTO num_backets BUCKETS:指定了桶的数量num_bucket。数据将分配到指定数量的桶中,以便并行存储和查询。
根据表中某一列的哈希函数,将每个分区或未分区表划分为多个桶。实际上,每个桶只是分区目录或表目录(未分区表)中的一个文件。因此,如果选择将分区划分为 n 个桶,那么每个分区目录中就会有 n 个文件。
例如,上图中,我们将每个分区分为 2 个桶,每个分区(如 Medicine)都将有两个文件,每个文件都将存储 Medicine 院系的学生数据。
Hive 为何使用 buckets ?
对分区执行分桶操作主要有两个原因:
- 映射侧连接要求属于唯一连接键的数据存在于同一分区中。但如果分区键与连接键不同,就可以使用连接键对表进行分桶,从而执行映射侧连接。
- 分桶使采样过程更加高效,可以减少查询时间。
Hive 如何将行分配到 buckets ?
Hive 通过以下公式确定行的桶数:
hash_funciton(bucketing_column) modulo(num_of_buckets)
说明:描述了在使用分桶时如何将数据行映射到特定的桶中的过程。
hash_function():针对列bucketing_column进行分桶,应用一个哈希函数hash_function来计算其哈希值。哈希函数会将桶化列的值映射到一个固定范围的哈希码。modulo(num_of_buckets):num_of_buckets指定桶的数量,通过取模modulo操作确定要映射的桶。将哈希值映射到指定的桶。
例如,如果要根据某列(如 user_id,数据类型为 INT)对表进行分桶,则 hash_function 将为 hash_function (user_id) = user_id 的整数值。如果创建两个数据桶,那么 Hive 将通过计算 (user_id 的值) modulo(2) 来确定每个分区中进入数据桶 1 的记录。因此,这种情况下, user_id 以偶数结尾的行记录将存放在每个分区对应的数据桶 1 中。