大数据平台之 HiveSQL
Hive 简介
Hive 是 Facebook 开源的一款基于 Hadoop 的数据仓库工具,是目前应用最广泛的大数据处理解决方案。它能将 SQL 查询转变为 MapReduce(Google 提出的一个软件架构,用于大规模数据集的并行运算)任务,对 SQL 提供了完美的支持,能够非常方便的实现大数据统计。
Hadoop 生态系统既不是一种编程语言,也不是一种服务,它是一个解决大数据问题的平台或框架。你可以将其视为一个套件,其中包含许多服务(如摄取、存储、分析和维护)。
以下是 Hadoop 组件,它们共同构成了 Hadoop 生态系统。
- HDFS -> Hadoop 分布式文件系统
- YARN -> 通过分配资源和调度任务执行处理活动
- MapReduce ->使用编程进行数据处理
- Spark ->内存数据处理
- PIG、HIVE ->使用查询(类似 SQL)的数据处理服务
- HBase -> NoSQL 数据库
- Mahout、Spark MLlib ->机器学习
- Apache Drill -> Hadoop 上的 SQL
- Zookeeper ->管理集群
- Oozie ->作业调度
- Flume、Sqoop ->数据摄取服务
- Solr 和 Lucene ->搜索和索引
- Ambari ->配置、监控和维护集群
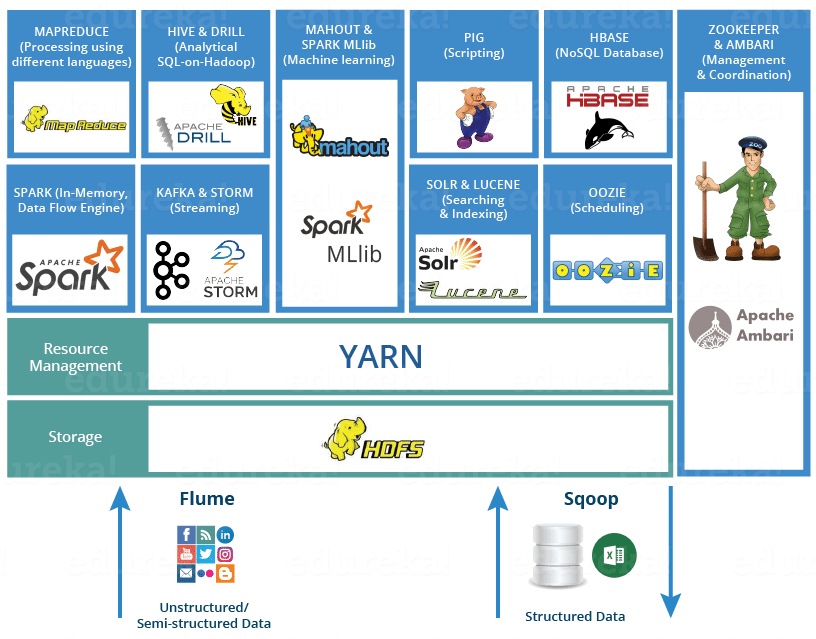
说明:了解学习 Hadoop 生态系统
简单介绍 Hive 的两个核心点:
- 将 HDFS 中结构化的数据映射成表。
- 通过把 Hive-SQL 进行解析和转换,生成一系列基于 Hadoop 的 MapReduce 任务/Spark 任务。通过执行这些任务完成对数据的处理。即使没有学习相关编程语言,也可以实现对数据的处理。
Hive 和传统关系型数据库对比所示:
| Hive | RDBMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 存储数据 | HDFS | 本地文件系统 |
| 执行方式 | MapReduce / Spark | Executor |
| 执行延迟 | 高 | 低 |
| 数据规模 | 大 | 小 |
Hive 平台搭建
搭建如下图的大数据平台:

准备工作:
- [[Hadoop/HDFS 集群部署|HDFS 集群部署]]
- [[../Hadoop/Apache Hive 安装配置|Apache Hive 安装配置]]
Hive 基本用法
Hive 查询语言 (HQL)可以帮助用户定义表结构、查询数据并进行数据处理。
Hive 的数据类型
基本数据类型:
| 数据类型 | 占用空间 | 支持版本 |
|---|---|---|
| tinyint | 1-Byte | |
| smallint | 2-Byte | |
| int | 4-Byte | |
| bigint | 8-Byte | |
| boolean | ||
| float | 4-Byte | |
| double | 8-Byte | |
| string | ||
| binary | 0.8版本 | |
| timestamp | 0.8版本 | |
| decimal | 0.11版本 | |
| char | 0.13版本 | |
| varchar | 0.12版本 | |
| date | 0.12版本 |
复杂数据类型:
| 数据类型 | 描述 | 例子 |
|---|---|---|
| struct | 和C语言中的结构体类似 | struct<first_name:string, last_name:string> |
| map | 由键值对构成的元素的集合 | map<string,int> |
| array | 具有相同类型的变量的容器 | array<string> |
常用函数
- 时间和日期函数:如
from_unixtime,unix_timestamp,datediff,这些函数用来转换和操作日期时间数据。from_unixtime: 将 Unix 时间戳转换为人类可读的日期格式。例如:from_unixtime(1609459200)可能会返回2021-01-01 00:00:00。unix_timestamp: 将日期转换为 Unix 时间戳。例如:unix_timestamp('2021-01-01 00:00:00')返回相应的时间戳。datediff: 计算两个日期的天数差。例如:datediff('2021-01-10', '2021-01-01')返回9。
- 字符串函数:如
substr,用于字符串处理。 - 条件函数:如
if,用于条件判断和控制流。 - JSON 处理函数:如
get_json_object,用于从 JSON 数据中提取信息。
连接 HiveServer2
连接 HiveServer2 服务器实例,进入 beeline 命令行环境:
beeline -u jdbc:hive2://localhost:10000
说明:beeline 是一个用来连接和访问 Apache Hive 的命令行工具,用来执行 HiveQL 查询。
创建数据库
create database demo;
进入数据库
use demo;
创建和使用表
内部表
创建内部表 user_info:
create table if not exists user_info
(
user_id string,
user_name string,
sex string,
age int,
city string,
firstactivetime string,
level int,
extra1 string,
extra2 map<string,string>
)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile;
说明:
extra2 map<string,string>:键值对数据类型字段。row format delimited fields terminated by '\t'- 其中,
row format delimited表示声明数据的行格式是“分隔的”,即数据行中的字段使用某种分隔符进行分隔。 fields terminated by '\t'指定字段之间的分隔符为制表符\t。
- 其中,
collection items terminated by ','表示集合项使用逗号分隔。map keys terminated by ':'表示键值对之间使用冒号分隔。lines terminated by '\n'表示行之间使用换行符分隔。stored as textfile表示以文本文件的形式存储。
查看表的元数据信息:
DESCRIBE FORMATTED user_info
创建数据文件:
以定义的 user_info 数据表结构形式在本地创建一个 /usr/user_info.txt 数据文件。
001 张三 男 25 武汉 2024-04-22 3 extra1_value1 extra2_key1:value1,extra2_key2:value2
002 李四 男 26 南京 2024-04-23 2 extra1_value2 extra2_key3:value3,extra2_key4:value4
003 王五 女 27 长沙 2024-04-25 4 extra1_value3 extra2_key5:value5,extra2_key6:value6
复制数据文件到分布式系统:
将本地文件系统中的 /usr/user_info.txt 复制到目标分布式文件系统中。
hdfs dfs -put /usr/user_info/user_info.txt /user/user_info.txt
分布式系统中加载数据:
将 HDFS 中的文件数据加载到表格中。
0: jdbc:hive2://localhost:10000> load data inpath '/user/user_info.txt' overwrite into table user_info;
注意:将文件数据加载到数据表中,原始路径文件会被移除。。
查询数据表:
0: jdbc:hive2://localhost:10000> show tables;
...
+------------+
| tab_name |
+------------+
| user_info |
+------------+
1 row selected (7.373 seconds)
查询内部表所有数据:
0: jdbc:hive2://localhost:10000> select * from user_info;
...
+--------------------+----------------------+----------------+----------------+-----------------+----------------------------+------------------+-------------------+--------------------------------------------------+
| user_info.user_id | user_info.user_name | user_info.sex | user_info.age | user_info.city | user_info.firstactivetime | user_info.level | user_info.extra1 | user_info.extra2 |
+--------------------+----------------------+----------------+----------------+-----------------+----------------------------+------------------+-------------------+--------------------------------------------------+
| 001 | 张三 | 男 | 25 | 武汉 | 2024-04-22 | 3 | extra1_value1 | {"extra2_key1":"value1","extra2_key2":"value2"} |
| 002 | 李四 | 男 | 26 | 南京 | 2024-04-23 | 2 | extra1_value2 | {"extra2_key3":"value3","extra2_key4":"value4"} |
| 003 | 王五 | 女 | 27 | 长沙 | 2024-04-25 | 4 | extra1_value3 | {"extra2_key5":"value5","extra2_key6":"value6"} |
+--------------------+----------------------+----------------+----------------+-----------------+----------------------------+------------------+-------------------+--------------------------------------------------+
3 rows selected (16.241 seconds)
检查数据库 hivedb:
- 进入 MySQL ,切换至数据库
hivedb:
mysql> use hivedb;
Database changed
mysql> show tables;
+-------------------------------+
| Tables_in_hivedb |
+-------------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_METRICS_CACHE |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| CTLGS |
| DATABASE_PARAMS |
| DATACONNECTORS |
| DATACONNECTOR_PARAMS |
| DBS |
| DB_PRIVS |
| DC_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| I_SCHEMA |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| MATERIALIZATION_REBUILD_LOCKS |
| METASTORE_DB_PROPERTIES |
| MIN_HISTORY_LEVEL |
| MIN_HISTORY_WRITE_ID |
| MV_CREATION_METADATA |
| MV_TABLES_USED |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_WRITE_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PACKAGES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| REPLICATION_METRICS |
| REPL_TXN_MAP |
| ROLES |
| ROLE_MAP |
| RUNTIME_STATS |
| SCHEDULED_EXECUTIONS |
| SCHEDULED_QUERIES |
| SCHEMA_VERSION |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| STORED_PROCS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TXN_LOCK_TBL |
| TXN_TO_WRITE_ID |
| TXN_WRITE_NOTIFICATION_LOG |
| TYPES |
| TYPE_FIELDS |
| VERSION |
| WM_MAPPING |
| WM_POOL |
| WM_POOL_TO_TRIGGER |
| WM_RESOURCEPLAN |
| WM_TRIGGER |
| WRITE_SET |
+-------------------------------+
83 rows in set (0.38 sec)
- 查询 Hive 所有数据库:
mysql> select * from DBS;
+-------+-----------------------+--------------------------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME | CREATE_TIME | DB_MANAGED_LOCATION_URI | TYPE | DATACONNECTOR_NAME | REMOTE_DBNAME |
+-------+-----------------------+--------------------------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
| 1 | Default Hive database | hdfs://hadoop01:8020/user/hive/warehouse | default | public | ROLE | hive | 1713718303 | NULL | NATIVE | NULL | NULL |
| 11 | NULL | hdfs://hadoop01:8020/user/hive/warehouse/demo.db | demo | anonymous | USER | hive | 1713718874 | NULL | NATIVE | NULL | NULL |
+-------+-----------------------+--------------------------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
2 rows in set (0.16 sec)
- 查询 Hive 数据库所有表:
mysql> select * from TBLS;
+--------+-------------+-------+------------------+-----------+------------+-----------+-------+-----------+----------------+--------------------+--------------------+--------------------+----------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED | WRITE_ID |
+--------+-------------+-------+------------------+-----------+------------+-----------+-------+-----------+----------------+--------------------+--------------------+--------------------+----------+
| 1 | 1713718965 | 11 | 0 | anonymous | USER | 0 | 1 | user_info | EXTERNAL_TABLE | NULL | NULL | | 0 |
| 2 | 1713729509 | 1 | 0 | anonymous | USER | 0 | 2 | user_info | EXTERNAL_TABLE | NULL | NULL | | 0 |
+--------+-------------+-------+------------------+-----------+------------+-----------+-------+-----------+----------------+--------------------+--------------------+--------------------+----------+
2 rows in set (0.03 sec)
- 查询 Hive 数据库表中字段:
mysql> select * from COLUMNS_V2;
+-------+---------+-----------------+--------------------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-----------------+--------------------+-------------+
| 1 | NULL | age | int | 3 |
| 1 | NULL | city | string | 4 |
| 1 | NULL | extra1 | string | 7 |
| 1 | NULL | extra2 | map<string,string> | 8 |
| 1 | NULL | firstactivetime | string | 5 |
| 1 | NULL | level | int | 6 |
| 1 | NULL | sex | string | 2 |
| 1 | NULL | user_id | string | 0 |
| 1 | NULL | user_name | string | 1 |
| 2 | NULL | age | int | 3 |
| 2 | NULL | city | string | 4 |
| 2 | NULL | extra1 | string | 7 |
| 2 | NULL | extra2 | map<string,string> | 8 |
| 2 | NULL | firstactivetime | string | 5 |
| 2 | NULL | level | int | 6 |
| 2 | NULL | sex | string | 2 |
| 2 | NULL | user_id | string | 0 |
| 2 | NULL | user_name | string | 1 |
+-------+---------+-----------------+--------------------+-------------+
18 rows in set (0.00 sec)
外部表
使用 Hive 语句用于创建一个外部表 ex_access,并定义其数据结构和存储位置。
create external table ex_access(ip string,url string,access_time string)
row format delimited
fields terminated by ','
location '/user/log';
说明:LOCATION 关键字用于指定外部表数据存储的位置。在本例中,意味着 Hive 将在 HDFS 中 /user/log 目录中查找表的数据文件。
分区表
创建分区表:
create table if not exists user_trade
(
user_name string,
piece int,
price double,
pay_amount double,
goods_category string,
pay_time bigint
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
说明:
partitioned by (dt string):表格将按照dt字段进行分区,dt字段的数据类型为string。- 在本例中,假定
dt字段存储的是交易发生的日期,那么每个不同的日期值将对应一个分区。这样可以将数据按照日期进行分开存储,方便进行按日期的查询或管理,而不用扫描整个表内容。
- 在本例中,假定
在 Hive 中,分区将表的数据按照某个字段的值进行逻辑上的划分,每个不同的字段值对应一个分区。这种逻辑上的划分可以帮助优化查询性能和管理数据。
设置动态分区:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
说明:通常在 Hive 的配置文件如 hive-site.xml 中配置,用于控制 Hive 在执行动态分区操作时的行为。
- 若使用
set命令设置仅在当前会话中生效。 hive.exec.dynamic.partition设置为true:启用动态分区插入功能。动态分区插入是指在将数据加载到分区表时,根据数据中的值动态创建新的分区。hive.exec.dynamic.partition.mode设置为nostrict:设置动态分区插入的模式为非严格模式。在非严格模式下,如果动态插入时没有指定所有分区列的值,则会将数据插入到一个特殊的分区中。hive.exec.max.dynamic.partitions=10000;: 设置单个动态分区插入操作可以创建的最大动态分区数。hive.exec.max.dynamic.partitions.pernode=10000;: 设置每个节点上单个动态分区插入操作可以创建的最大动态分区数。
创建分区数据文件:
以 user_trade 分区表结构在本地文件系统上创建数据文件。
如第一个分区数据文件 /usr/user_trade/2024-04-22_trade_data.txt:
张三 2 10.5 21.0 电子产品 1713733200
李四 1 20.0 20.0 家居用品 1713740400
说明:
- 一般最后一个字段
dt是分区字段,如果不需要在数据文件中指定分区值,可以在加载数据时通过其他方式指定。
第二个分区数据文件 /usr/user_trade/2024-04-23_trade_data.txt:
王五 3 15.8 47.4 食品 1713823566
赵六 1 30.0 30.0 服装 1713819600
上传数据文件到分布式系统:
将本地文件系统的分区数据文件内容上传到 HDFS 目录。
[root@hadoop02 ~]# hdfs dfs -put -f /usr/user_trade/* /user/hive/warehouse/demo.db/user_trade
说明:-f 表示强制覆盖已存在的文件并上传新文件。
向分区中导入数据:
load data inpath '/user/hive/warehouse/demo.db/user_trade/2024-04-22_trade_data.txt' into table user_trade partition(dt='2024-04-22');
load data inpath '/user/hive/warehouse/demo.db/user_trade/2024-04-23_trade_data.txt' into table user_trade partition(dt='2024-04-23');
修复分区表元数据:
在 Hive 中,如果手动添加了新的分区,或者分区目录的结构发生变化,但元数据没有及时更新,需要使用 msck repair table 命令修复表的元数据,使得 Hive 能够正确识别和管理这些分区。
0: jdbc:hive2://localhost:10000> msck repair table user_trade;
查询分区表:
- 查询分区表所有数据:
0: jdbc:hive2://localhost:10000> select * from user_trade;
...
+-----------------------+-------------------+-------------------+------------------------+----------------------------+----------------------+----------------+
| user_trade.user_name | user_trade.piece | user_trade.price | user_trade.pay_amount | user_trade.goods_category | user_trade.pay_time | user_trade.dt |
+-----------------------+-------------------+-------------------+------------------------+----------------------------+----------------------+----------------+
| 张三 | 2 | 10.5 | 21.0 | 电子产品 | 1713733200 | 2024-04-22 |
| 李四 | 1 | 20.0 | 20.0 | 家居用品 | 1713740400 | 2024-04-22 |
| 王五 | 3 | 15.8 | 47.4 | 食品 | 1713823566 | 2024-04-23 |
| 赵六 | 1 | 30.0 | 30.0 | 服装 | 1713819600 | 2024-04-23 |
+-----------------------+-------------------+-------------------+------------------------+----------------------------+----------------------+----------------+
4 rows selected (6.807 seconds)
-
查询分区表
2024-04-23分区内容:将
dt当成表格字段,使用where 子句指定特定分区dt。
0: jdbc:hive2://localhost:10000> select user_name, price, goods_category, pay_time from user_trade where dt='2024-04-23';
...
+------------+--------+-----------------+-------------+
| user_name | price | goods_category | pay_time |
+------------+--------+-----------------+-------------+
| 王五 | 15.8 | 食品 | 1713823566 |
| 赵六 | 30.0 | 服装 | 1713819600 |
+------------+--------+-----------------+-------------+
2 rows selected (5.074 seconds)
删除数据库
若需要删除数据库,执行命令:
0: jdbc:hive2://localhost:10000> use demo1;
0: jdbc:hive2://localhost:10000> show tables;
...
+------------+
| tab_name |
+------------+
| user_info |
+------------+
1 row selected (3.961 seconds)
0: jdbc:hive2://localhost:10000> drop table user_info;
0: jdbc:hive2://localhost:10000> drop database if exists demo1;
注意:在 Hive 中,如果想要删除一个非空数据库,必须先删除其中的所有表,然后再删除数据库本身。
若删除数据,执行命令:
0: jdbc:hive2://localhost:10000> delete from user_trade;
Error: Error while compiling statement: FAILED: SemanticException [Error 10294]: Attempt to do update or delete using transaction manager that does not support these operations. (state=42000,code=10294)
0: jdbc:hive2://localhost:10000> truncate table user_trade;
说明:在 Hive 中,DELETE 语句通常不支持直接删除行数据,因为 Hive 表的设计更适合批量处理和数据加载而不是单个行的增删改查。如果要删除表中的数据,常见的做法使用 TRUNCATE TABLE 语句清空表中所有的数据,或直接删除整张表。
Hive 脚本
[[Hadoop/Hive 脚本|Hive 脚本]]基本使用方法。
参考
问题
问题1:查询数据表只指定某一字段结果却返回了其他字段的数据,或指定的某些字段返回结果却是异常 Null?
分析解决:可能是数据表定义使用固定的分隔符(比如制表符),但数据字段内容分隔填充时未按预期的方式填充。另外,通过使用
describe formatted table_name;命令查询表的详细信息,确保字段分隔符是否正确配置。