数据可视化
通过数据透视,可以将原始数据根据某些关键字段进行聚合、分组和排序,得到更直观的结果。随后,可以使用可视化工具(如 matplotlib)将数据透视的结果以图表形式展示,帮助更好地分析数据趋势和模式。例如,可以使用柱状图、饼图或折线图来展示数据的分布或变化,从而简化数据解释并支持决策分析。
图表类型
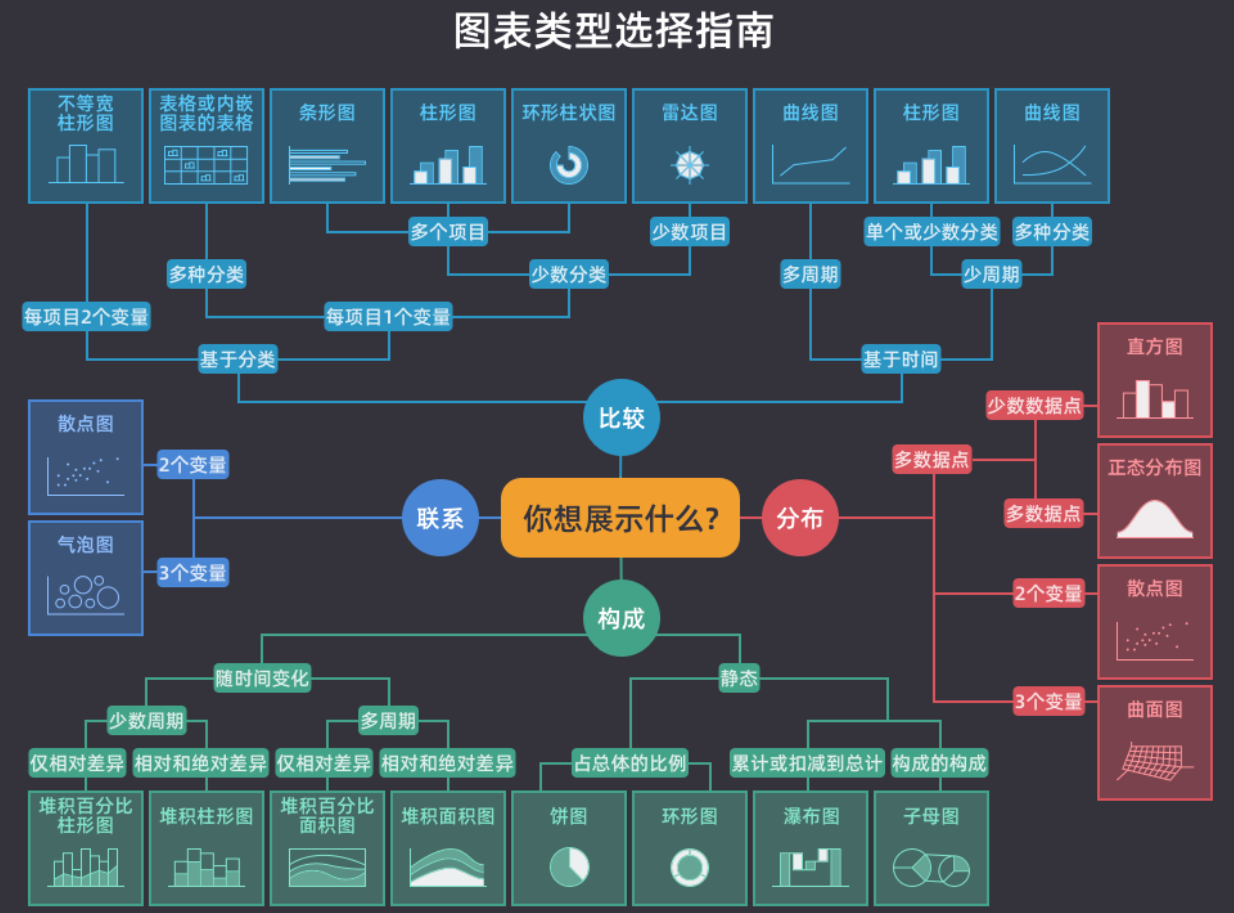
常见的图表类型及其应用场景,如下图所示:
Matplotlib 配置
首先,确保已经安装 matplotlib 库,命令如下:
pip install matplotlib
导入 matplotlib.pyplot 模块并做必要配置。可参考之前[[Pandas的应用#创建图表|创建图表内容]]。
import matplotlib.pyplot as plt
# 配置支持中文的非衬线字体(默认的字体无法显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei',]
# 设置负号显示防止使用中文字体时负号无法显示的问题
plt.rcParams['axes.unicode_minus'] = False
使用 Jupyter Notebook 魔法命令用于配置绘图后端的显示格式。 可以将绘图后端的默认输出格式设置为矢量图。
# 配置绘图后端输出格式为 SVG
%config InlineBackend.figure_format='svg'
绘图流程
创建画布
创建一个自定义的图形窗口画布。
plt.figure(figsize=(8, 4), dpi=120, facecolor='darkgray')
说明:
figsize=(8, 4):定义图形的宽度和高度,单位是英寸。dpi=120:定义每英寸的点数(dots per inch),用于设置图形的分辨率。值越高,图形的分辨率越高。facecolor='darkgray':定义图形背景的颜色。本例,设置为深灰色。
输出:
<Figure size 960x480 with 0 Axes>
<Figure size 960x480 with 0 Axes>
创建坐标系
在一个图形窗口中创建一个包含多个子图的布局,并选择其中一个子图进行绘制。
plt.subplot(2, 2, 1)
说明:
- 使用
pyplot模块的subplot函数创建坐标系,该函数返回Axes对象。 subplot的前三个参数分别指定整个画布分成几行几列即当前坐标系的索引。本例各个参数的含义:2:行数。表示子图布局中包含 2 行。2:列数。表示子图布局中包含 2 列。1:子图的索引。表示选择第一个子图进行绘制。
- 也可以通过
Figure对象的add_subplot方法或add_axes方法来创建坐标系,前者跟subplot函数的作用一致,后者会产生嵌套的坐标系。
输出:

绘制图像
折线图
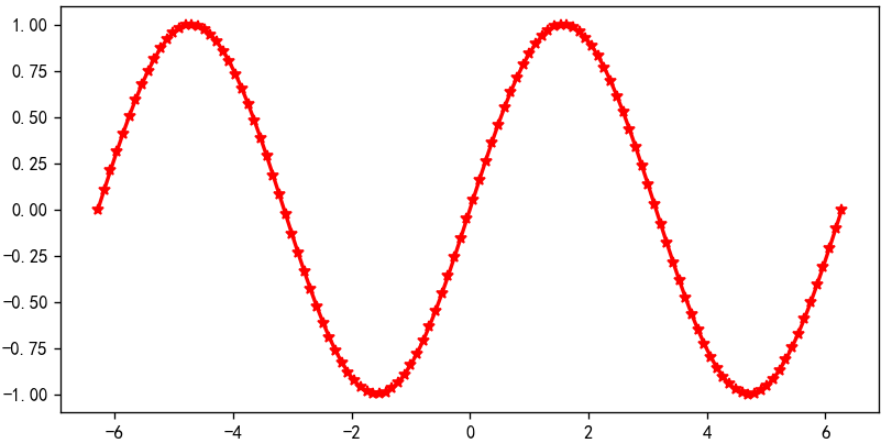
例如,绘制一条正弦曲线,数据点标记设置为五角星的形状,绘制折线显示红色。
import numpy as np
# 生成从-2π到2π之间的120均匀分布的点
x = np.linspace(-2 * np.pi, 2 * np.pi ,120)
y = np.sin(x)
# 创建画布
plt.figure(figsize=(8, 4), dpi=120)
# 绘制折线图
plt.plot(x, y, linewidth=2, marker='*', color='red')
# 显示绘图
plt.show()
说明:
plt.plot(x, y, linewidth=2, marker='*', color='red')绘制折线图:x和y分别是横坐标和纵坐标的数据。linewidth=2设置线宽为 2。marker='*'设置数据点的标记为星号,例如^表示三角形,o表示小圆圈等。color='red'设置线条和标记的颜色为红色。linestyle参数可以指定折线的样式,例如-表示实线,--表示虚线,:表示点线等
输出:
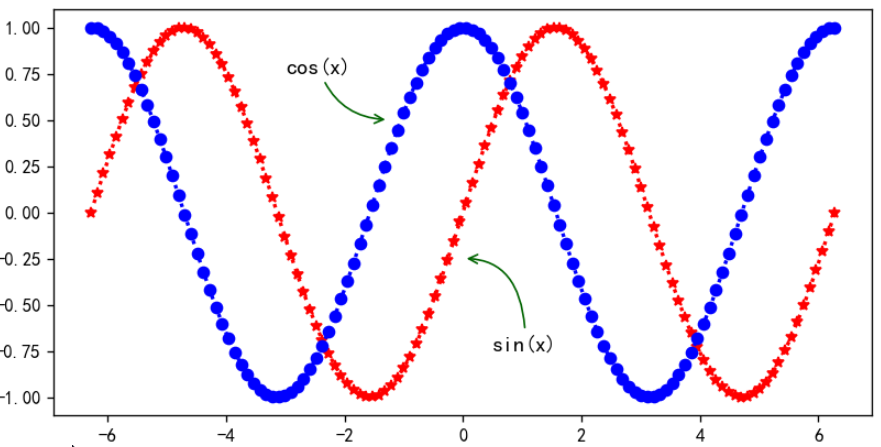
在一个坐标系上同时绘制正弦和余弦曲线。
import numpy as np
# 生成从-2π到2π之间的120均匀分布的点
x = np.linspace(-2 * np.pi, 2 * np.pi ,120)
y1, y2 = np.sin(x), np.cos(x)
# 创建画布
plt.figure(figsize=(8, 4), dpi=120)
# 绘制折线图
plt.plot(x, y1, linewidth=2, marker='*', color='red', linestyle=':')
plt.plot(x, y2, linewidth=2, marker='o', color='blue', linestyle=':')
# 定制图表的标注其中arrowprops是定制箭头样式的参数
plt.annotate('sin(x)', xytext=(0.5, -0.75), xy=(0, -0.25), fontsize=12, arrowprops={
'arrowstyle': '->', 'color': 'darkgreen', 'connectionstyle': 'angle3, angleA=90, angleB=0'
})
plt.annotate('cos(x)', xytext=(-3, 0.75), xy=(-1.25, 0.5), fontsize=12, arrowprops={
'arrowstyle': '->', 'color': 'darkgreen', 'connectionstyle': 'arc3, rad=0.35'
})
# 显示绘图
plt.show()
说明:
plt.annotate()为图表添加注释:xytext指定注释文字的位置。xy指定被注释点的位置。arrowroups用于定制箭头的样式:arrowstyle='->'设置箭头样式。color='darkgreen'设置箭头颜色。connectionstyle='angle3, angleA=90, angleB=0'设置箭头的连接样式。
输出:
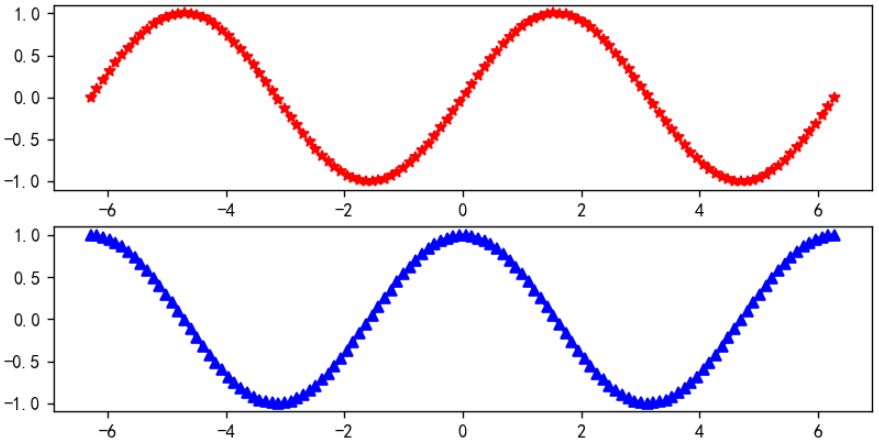
在两个坐标系分别绘制正弦和余弦曲线,使用 subplot 函数创建坐标系,然后绘图。
plt.figure(figsize=(8, 4), dpi=120)
# 创建坐标系,图1
plt.subplot(2, 1, 1)
plt.plot(x, y1, linewidth=2, marker='*', color='red', linestyle='--')
# 创建坐标系,图2
plt.subplot(2, 1, 2)
plt.plot(x, y2, linewidth=2, marker='^', color='blue', linestyle='--')
plt.show()
输出:
在两个坐标系左右位置分别绘制正弦和余弦曲线,代码如下:
plt.figure(figsize=(8, 4), dpi=120)
plt.subplot(1, 2, 1)
plt.plot(x, y1, linewidth=2, marker='*', color='red')
plt.subplot(1, 2, 2)
plt.plot(x, y2, linewidth=2, marker='^', color='blue')
plt.show()
散点图
散点图可以帮助我们了解两个变量的关系,如果需要了解三个变量的关系,可以将散点图升级为气泡图。
x = np.array([5550, 7500, 10500, 15000, 20000, 25000, 30000, 40000])
y = np.array([800,1800,1250,2000,1800,2100,2500,3500])
plt.figure(figsize=(6, 4), dpi=120)
# 绘制 x 和 y 数据点的散点图
plt.scatter(x, y)
plt.show()
输出:
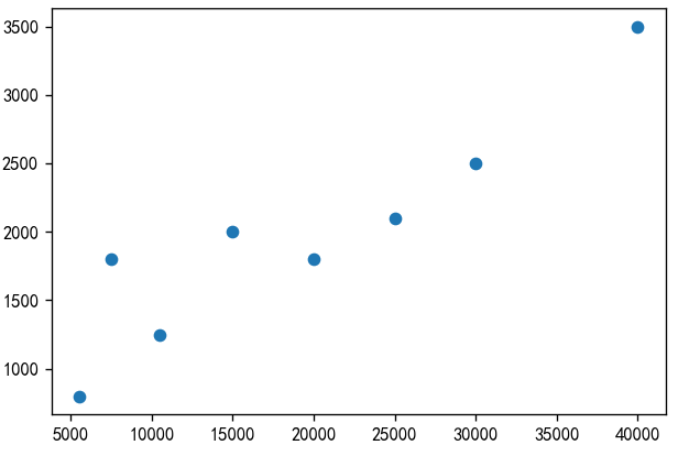
柱状图
在对比数据的差异时,可以选择柱状图。可以使用 pyplot 模块的 bar 函数生成柱状图,也可以使用 barh 函数生成水平柱状图。
绘制柱状图代码如下:
x = np.arange(4)
y1 = np.random.randint(10, 50, 4)
y2 = np.random.randint(20, 60, 4)
plt.figure(figsize=(6, 4), dpi=120)
# 通过横坐标的偏移让两组数据对应的柱形图分开
# width参数指定柱子的粗细,label参数为柱子添加标签
plt.bar(x - 0.1, y1, width=0.2, label='销售a')
plt.bar(x + 0.1, y2, width=0.2, label='销售b')
# 定制横轴的刻度
plt.xticks(x, labels=['Q1', 'Q2', 'Q3', 'Q4'])
# 定制显示图例
plt.legend()
# 显示图表
plt.show()
输出:
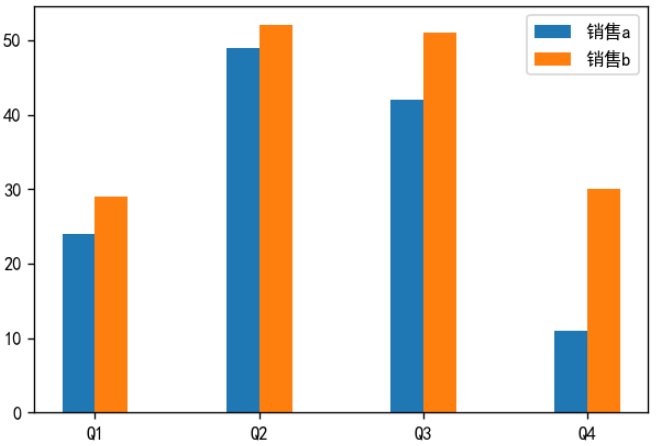
绘制堆叠柱状图,代码如下:
# 创建数据
y1 = np.random.randint(10, 50, 4)
y2 = np.random.randint(20, 60, 4)
labels = ['Q1', 'Q2', 'Q3', 'Q4']
# 创建画布
plt.figure(figsize=(6, 4), dpi=120)
# 绘制销售a的柱状图
plt.bar(labels, y1, width=0.4, label='销售a')
# 绘制销售b的堆叠柱状图
# 注意:堆叠柱状图的关键是将之前的柱子作为新柱子的底部
# 可以通过bottom参数指定底部数据,新柱子绘制在底部数据之上
plt.bar(labels, y2, width=0.4, bottom=y1, label='销售b')
# 添加图例
plt.legend(loc='upper right')
# 显示绘图
plt.show()
输出:
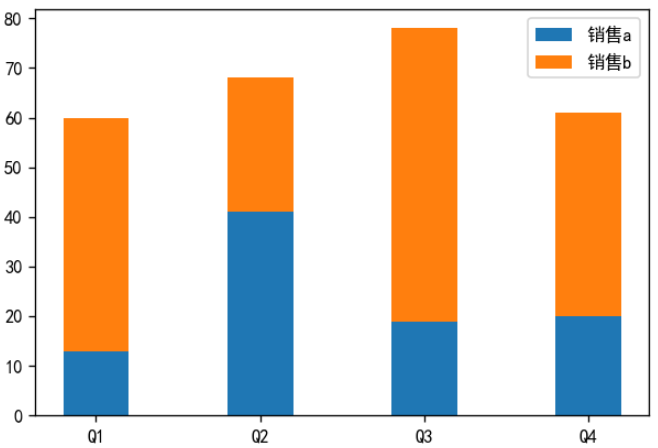
饼状图
饼状图也称饼图,是将数据划分为几个扇形区域的统计图表。它主要描述数量、频率等之间的关系。在饼状图中,每个扇形区域的大小就是其所表示的数量的比例,这些扇形区域合在一起刚好是一个完整的圆饼。
在需要展示数据构成的场景下,饼状图、树状图和瀑布图是不错的选择。
可以使用 pyplot 模块的 pie 函数绘制饼图,代码如下所示:
data = np.random.randint(100, 500, 7)
labels = ['苹果', '香蕉', '桃子', '荔枝', '石榴', '山竹', '榴莲']
plt.figure(figsize=(5, 5), dpi=120)
plt.pie(
# 饼图各部分的大小
data,
# 显示百分比格式
autopct='%.1f%%',
# 饼图的半径
radius=1,
# 百分比到圆心的距离
pctdistance=0.8,
# 随机生成颜色
colors=np.random.rand(7, 3),
# 指定突出显示的部分
explode=[0.05, 0, 0.1, 0, 0, 0, 0],
# 阴影效果
shadow=True,
# 字体属性
textprops=dict(fontsize=8, color='black'),
# 楔子属性
wedgeprops=dict(linewidth=1, width=0.35),
# 饼图各部分的标签
labels=labels
)
plt.title('水果销售额占比')
plt.show()
输出:
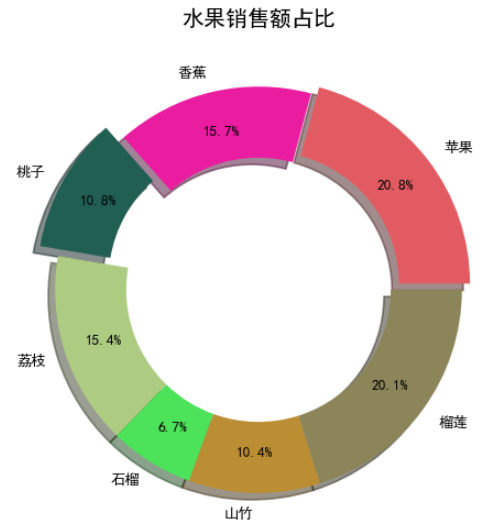
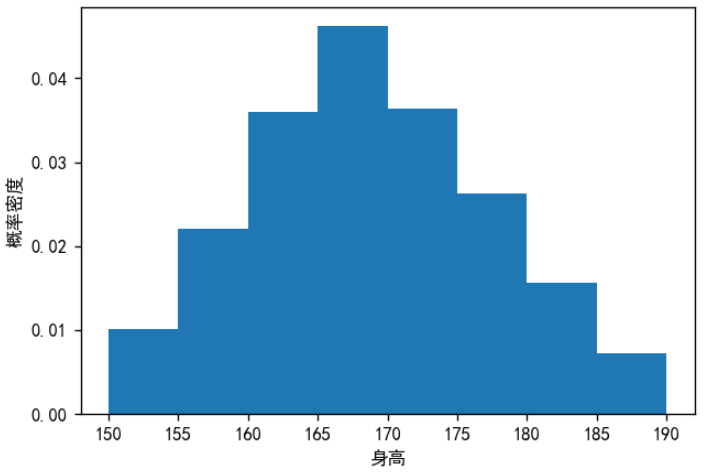
直方图
在统计学,直方图是一种展示数据分布情况的二维统计图表。它的两个坐标分别是统计样本和该样本对应的某个属性的度量。
例如,使用直方图展示某学校 500 名学生的身高的数据分布情况。使用 pyplot 模块的 hist 函数绘制直方图,代码如下所示:
# 生成身高数据,使其符合正态分布
mean = 168
std_dev = 10
heights = np.random.normal(loc=mean, scale=std_dev, size=500)
# 将身高数据分到8个组中
bins = np.array([150, 155, 160, 165, 170, 175, 180, 185, 190])
# 绘制直方图
plt.figure(figsize=(6, 4), dpi=120)
plt.hist(heights, bins, density=True)
# 定制横轴标签
plt.xlabel('身高')
# 定制纵轴标签
plt.ylabel('概率密度')
plt.show()
说明:
density=True表示直方图显示的是概率密度而不是频数。
输出:
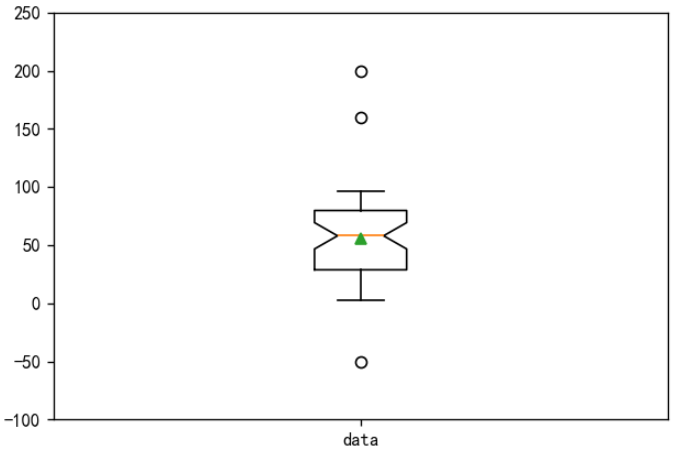
箱线图
箱线图也称箱型图或盒须图,是一种用于展示数据分布情况的统计图表,特别适合于比较多个数据集的分布情况。箱线图显示了数据的中位数、四分位数、最小值、最大值及异常值等信息。
箱线图的组成部分
-
箱体(Box):
- 中位数(Median):箱体内部的一条线,表示数据的中位数(第二四分位数,Q2)。
- 第一四分位数(Q1):箱体的下边缘,表示数据的第 25 个百分位数。
- 第三四分位数(Q3):箱体的上边缘,表示数据的第 75 个百分位数。
- 四分位距(IQR):Q3 - Q1,表示箱体的高度,反映数据的离散程度。
-
须(Whiskers):
- 须从箱体延伸至数据的最小值和最大值,但须长度不超过 1.5 倍的四分位距(1.5 * IQR)。任何超过这个范围的值都被认为是异常值。
-
异常值(Outliers):
- 在箱体外的数据点,通常用单独的点标记出来。
箱线图的作用
- 显示数据的集中趋势:通过中位数和四分位数了解数据的分布和集中趋势。
- 识别数据的对称性:通过箱体和须的长度对比,可以看出数据是否对称分布。
- 检测异常值:箱线图能直观地显示出数据中的异常值。
绘制箱线图
使用 pyplot 模块的 boxplot 函数绘制箱线图,代码如下所示:
# 生成一个包含47个随机数的数组
data = np.random.randint(0, 100, 47)
# 向数组中添加可能的离群点数据
data = np.append(data, 160)
data = np.append(data, 200)
data = np.append(data, -50)
# 绘制箱线图
plt.figure(figsize=(6, 4), dpi=120)
plt.boxplot(data, whis=1.5, showmeans=True, notch=True)
# 定制纵轴的取值范围
plt.ylim([-100, 250])
# 定制横轴的刻度和标签
plt.xticks([1], labels=['data'])
plt.show()
说明:
plt.boxplot(data, whis=1.5, showmeans=True, notch=True):绘制箱线图。
whis=1.5:设置须的长度为1.5倍的四分位距。showmeans=True:在图中显示数据的均值。notch=True:在箱体的中间显示凹口,用于比较中位数的显著性。
输出:
显示或保存图像
使用 pyplot 模块的 show 函数可以显示绘制的图表,如果希望保存图表,可以使用 savefig 函数。需要注意的是,若同时显示和保存图表,应该先执行 savefig 函数,再执行 show 函数,因为 show 函数调用后,图表会被释放。
plt.savefig('chart.png')
plt.show()
其他图表
上述是一些使用频率最高的几类图表,使用 matplotlib 还可以绘制一些其他的统计图表。此外,matplotlib 还有很多对统计图表的定制细节,可以参考 matplotlib 官方文档。
可视化工具 Seaborn
Seaborn 是一个基于 Matplotlib 的高级数据可视化库,它简化了数据绘图的过程,并提供了美观、专业的图表。Seaborn 专注于让数据分析和数据科学家的工作更加轻松,尤其是与数据帧(DataFrame)等结构化数据配合使用时。
常用功能
-
分布图
distplot(): 绘制数据分布图。kdeplot(): 绘制核密度估计图。
-
分类图
barplot(): 绘制分类柱状图。countplot(): 绘制计数柱状图。boxplot(): 绘制箱线图。violinplot(): 绘制小提琴图。stripplot(): 绘制散点图。
-
回归图
regplot(): 绘制带有回归线的散点图。lmplot(): 绘制线性回归模型图。
-
矩阵图
heatmap(): 绘制热力图。clustermap(): 绘制聚类图。
-
多图合并
pairplot(): 绘制变量之间关系的矩阵图。FacetGrid: 创建一个多维度的网格图。
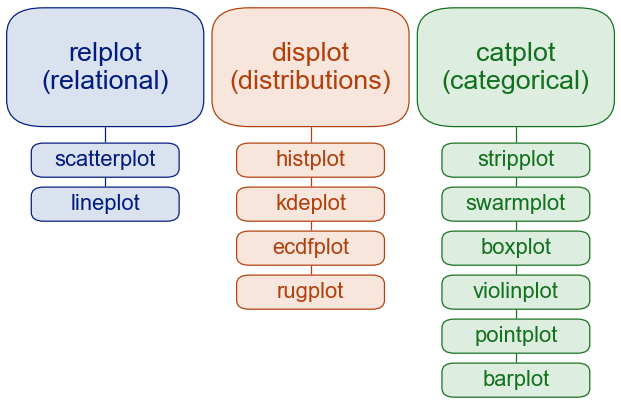
下图展示了 seaborn 绘制图表的函数,这些函数支持探索数据的关系、分布和分类来绘制图表。
可以通过 Python 的包管理器工具安装 seaborn。
pip install seaborn
使用 seaborn,导入库并设置主题;以及matplotlib 必要的参数配置。
import seaborn as sns
import matplotlib.pyplot as plt
# 设置主题
sns.set_theme()
# 配置支持中文的非衬线字体(默认的字体无法显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei',]
# 设置负号显示防止使用中文字体时负号无法显示的问题
plt.rcParams['axes.unicode_minus'] = False
如下用 seaborn 自带的数据为例,学习 seaborn 的一些用法。
加载官方的 Tips 数据集(就餐小费数据)
import ssl
# 由于数据集是联网加载的,可能会因为SSL原因无法获取到数据,优先执行如下代码
ssl._create_default_https_context = ssl._create_unverified_context
tips_df = sns.load_dataset('tips')
tips_df.info()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KB
说明:上述运行结果,其中,total_bill 表示账单总金额,tip 表示小费的金额,sex 表示顾客的性别,smoker 表示顾客是否抽样,day 表示星期几,time 代表用餐时间,size 代表就餐人数。
如果想了解账单金额的分布,可以绘制带有核密度估计(KDE)直方分布图。
sns.histplot(data=tips_df, x='total_bill', kde=True)
说明:
输出:

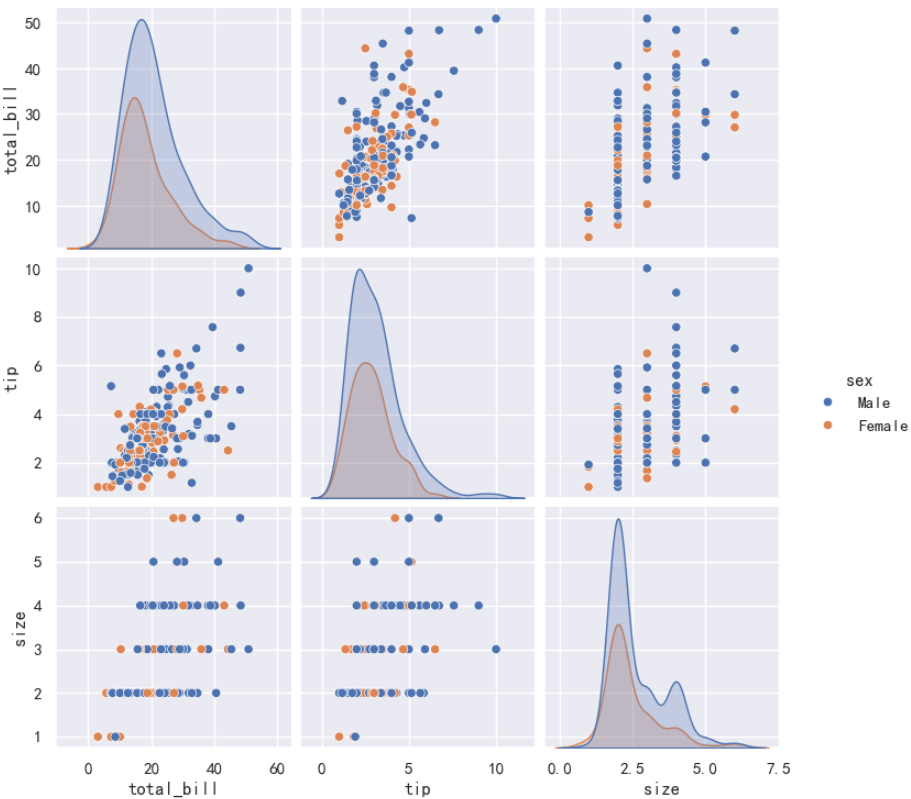
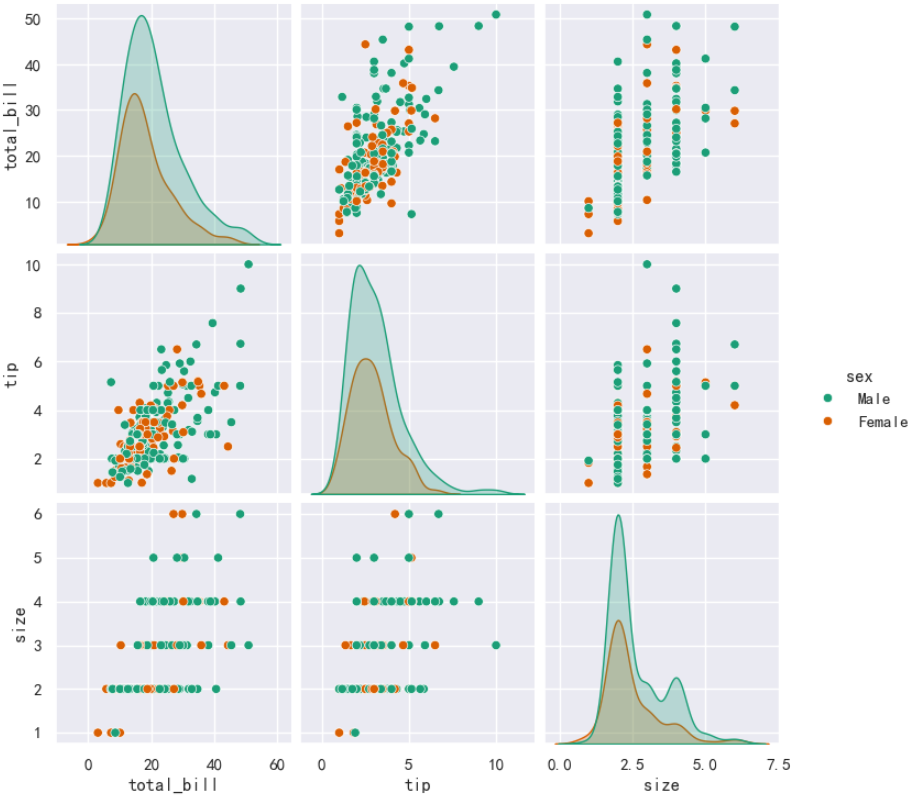
如果想了解变量之间的两两关系,如根据性别对数据进行着色,绘制成对关系图(pairplot)。
sns.pairplot(data=tips_df, hue='sex')
plt.show()
说明:hue=sex 指定根据 sex 列对数据进行着色。
输出:
如果想自定义图表颜色,还可以通过 palette 参数选择 seaborn 自带的调色板来修改颜色。
sns.pairplot(data=tips_df, hue='sex', palette='Dark2')
plt.show()
输出:
如果想展示两个变量的联合分布,同时在边缘显示每个变量的单变量分分布。
例如,展示 total_bill 和 tip 之间的关系,并根据 sex 对数据着色。绘制联合分布图,代码如下:
sns.jointplot(data=tips_df, x='total_bill', y='tip', hue='sex')
plt.show()
输出:
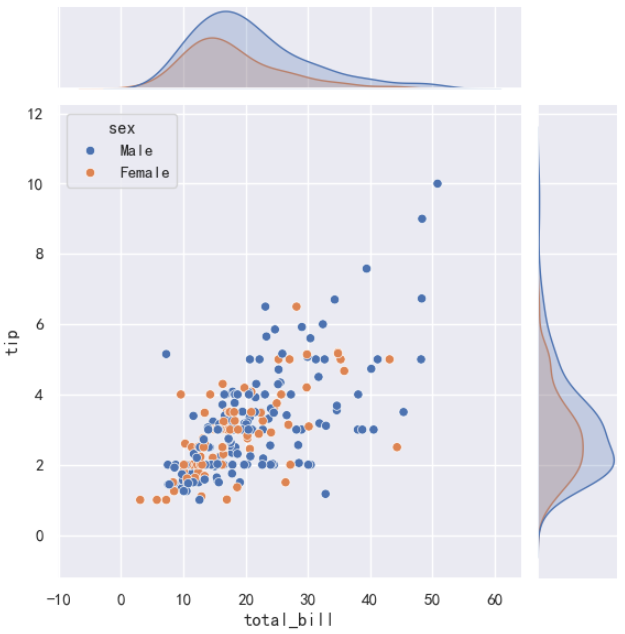
上述结果,清晰第展示了 total_bill 和 tip 之间存在正相关关系。
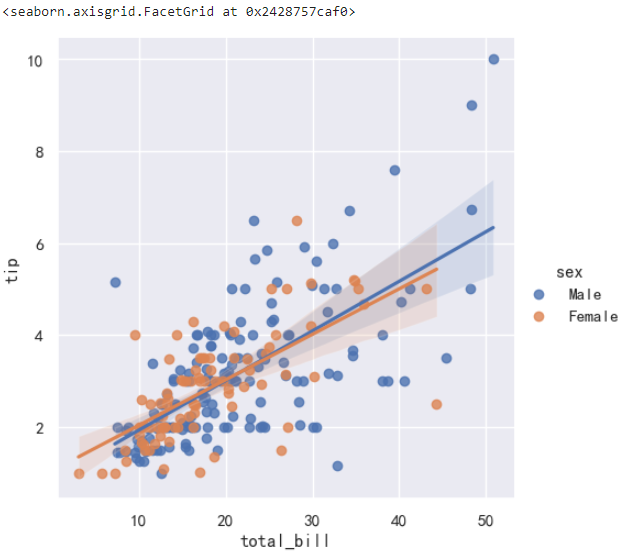
接下来,使用 seaborn 的线性回归拟合线的散点图来拟合这些数据点。
sns.lmplot(data=tips_df, x='total_bill', y='tip', hue='sex')
输出:
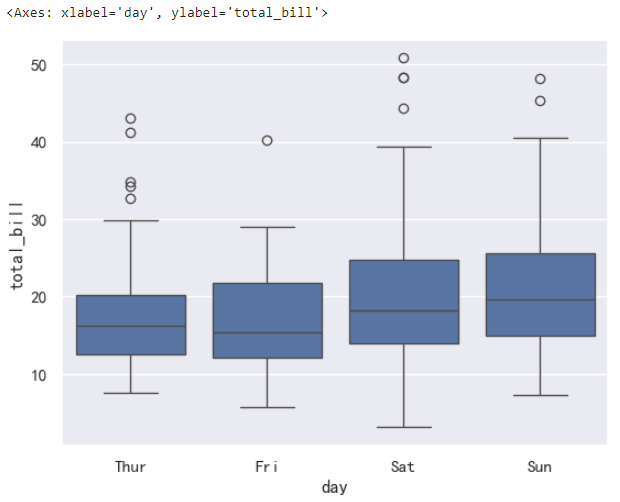
如果想了解账单金额的集中和离散趋势,可以绘制箱线图或小提琴图。将数据按照星期分别展示,代码如下:
sns.boxplot(data=tips_df, x='day', y='total_bill')
输出:
sns.violinplot(data=tips_df, x='day', y='total_bill')
输出:

说明:相对较于箱线图,小提琴图没有标注异常点而是显示了数据的整个范围;另外,小提琴图可以很好的展示数据密度轨迹的分布。
深入研究学习参考 seaborn 官方文档。
可视化工具 Pyecharts
Pyecharts 是一个用于生成 ECharts 图表的 Python 库,ECharts 是一个基于 JavaScript 的开源可视化图表库。Pyecharts 提供了简单的 Python 接口来生成各种类型的图表,例如折线图、柱状图、饼图等。
通过 Python 的包管理器安装 pyecharts:
pip install pyecharts
使用 Pyecharts 官方文档示例,学习一些 pyecharts 用法。
绘制图表,代码如下:
# 配置Pyecharts,设置渲染环境
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
from pyecharts.charts import Bar
from pyecharts import options as opts
# 内置主题类型可查看 pyecharts.globals.ThemeType
from pyecharts.globals import ThemeType
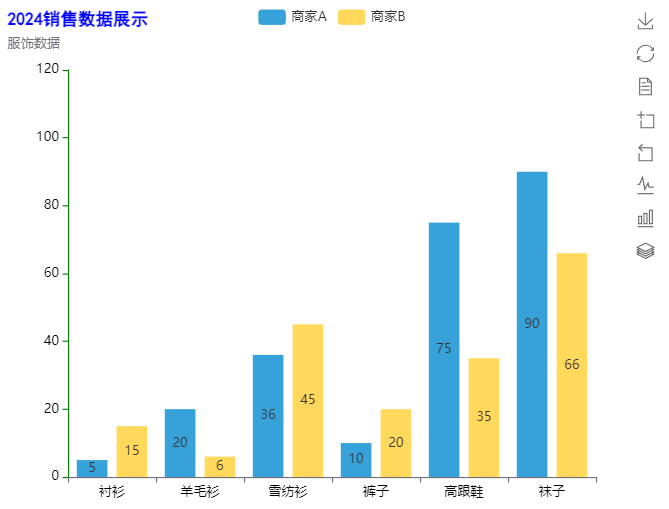
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT, width='600px'))
# 设置横轴数据
.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
# 设置纵轴数据(第一组)
.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])
# 设置纵轴数据(第二组)
.add_yaxis("商家B", [15, 6, 45, 20, 35, 66])
# 添加全局配置参数
.set_global_opts(
# 标题相关的参数(内容、链接、位置、文本样式)
title_opts=opts.TitleOpts(
title="2024销售数据展示", subtitle="服饰数据",
title_textstyle_opts=opts.TextStyleOpts(
color='blue',
font_size=16,
font_family='SimHei',
font_weight='bold'
)
),
# 工具箱相关的参数
toolbox_opts=opts.ToolboxOpts(
orient='vertical',
pos_left='right'
),
# 横轴相关的参数
xaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(color='black'),
),
# 纵轴相关的参数(标签、最大值、最小值、间隔等)
yaxis_opts=opts.AxisOpts(
# 网格线是否隐藏
splitline_opts=opts.SplitLineOpts(is_show=False),
# 坐标轴标签
axislabel_opts=opts.LabelOpts(color='black'),
# 坐标轴刻度
axistick_opts=opts.AxisTickOpts(
is_show=True
),
# 坐标轴刻度线
axisline_opts=opts.AxisLineOpts(
# 线条样式配置
linestyle_opts=opts.LineStyleOpts(color='green')
),
max_=120,
#min_=0,
#interval=10,
),
)
)
# 默认会在当前目录生成 render.html 文件
bar.render()
# 在Jupyte中首次渲染图表前加载js
bar.load_javascript()
和
# 在Jupyte中渲染图表
bar.render_notebook()
说明:
- 使用 Notebook 环境渲染图表时,需要在引入 pyecharts.charts 等模块前声明 Notebook 类型。并且可以参考在notebook中使用render_notebook()无法渲染出图片的问题。
- Jupyte 中渲染图表,如果已声明 Notebook 类型模型并也加载 JavaScript,还是无法渲染:将其他渲染生成图表的方式先屏蔽掉避免干扰,然后重新启动 Jupyter 程序。
输出:
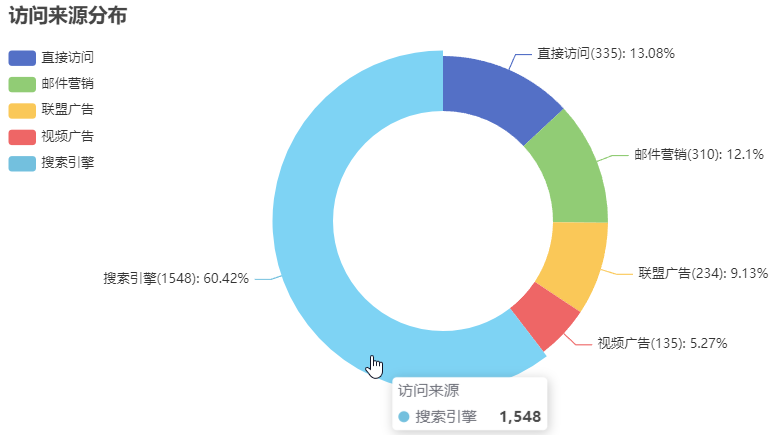
绘制饼图的示例,代码如下:
import pyecharts.options as opts
from pyecharts.charts import Pie
# 准备饼图需要的数据
x_data = ['直接访问', '邮件营销', '联盟广告', '视频广告','搜索引擎']
y_data = [335, 310, 234, 135, 1548]
data = [(x, y) for x, y in zip(x_data, y_data)]
# 创建饼图对象并设置初始化参数
pie = Pie(init_opts=opts.InitOpts(width='800px', height='400px'))
# 向饼图添加数据
pie.add(
'访问来源', # 指定饼图的数据系列的名称
data_pair=data,
radius=['50%', '75%'], # 饼图半径范围
label_opts=opts.LabelOpts(is_show=True, formatter='{b}({c}): {d}%') # 显示标签和格式
)
# 设置全局配置项
pie.set_global_opts(
title_opts=opts.TitleOpts(title='访问来源分布'), # 添加标题
legend_opts=opts.LegendOpts(
pos_left='left', # 图例组件离容器左侧的距离:水平居左
pos_top='10%', # 图例位于标题下方距离顶部10%
orient='vertical' # 图例排放方向为垂直
),
)
# 设置数据系列配置参数
pie.set_series_opts(
tooltip_opts=opts.TooltipOpts(is_show=True), # 启用工具提示
)
# 渲染图表
pie.render_notebook()
说明:
formatter参数用于指定标签或工具提示的文本格式。格式化字符串{b}({c}): {d}%:{b}: 数据项的名称(即饼图中的每一块的名称)。{c}: 数据项的值(即饼图中的每一块对应的数值)。{d}: 数据项的百分比(即数据项的值占总值的百分比)。
输出:
需要注意的是,pyecharts 并不能直接使用 Numpy 模块的
ndarray和 Pandas 的Series、DataFrame来提供数据,它需要使用 Python 原生的数据类型。
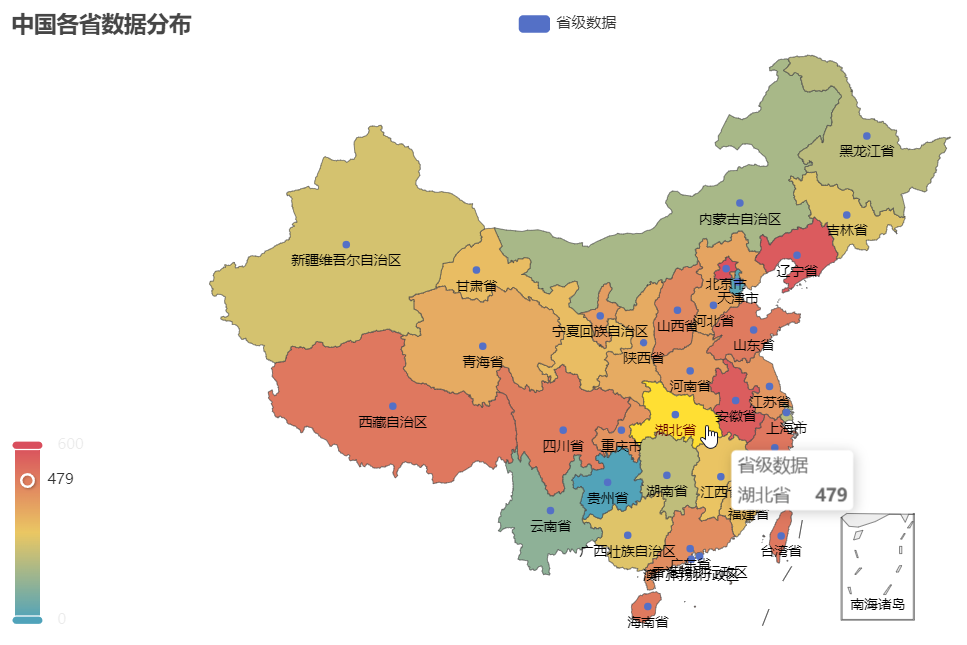
接下来,学习如何绘制地图。
绘制地图,首先要安装额外的依赖库用于可视化中国及其其他国家的地理数据。
pip install echarts-countries-pypkg echarts-china-provinces-pypkg echarts-china-cities-pypkg echarts-china-counties-pypkg
或在 Jupyter ,使用如下命令安装:
%pip install echarts-countries-pypkg
%pip install echarts-china-provinces-pypkg
%pip install echarts-china-cities-pypkg
%pip install echarts-china-counties-pypkg
说明:以上四个 Python 库,分别用于展示国家区域级别、中国各省级行政区、中国城市级别、中国县级行政区的地图数据。
# 配置Pyecharts,设置渲染环境
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
from pyecharts.charts import Map
from pyecharts import options as opts
import random
provinces = [
'北京市', '天津市', '河北省', '山西省', '内蒙古自治区',
'辽宁省', '吉林省', '黑龙江省', '上海市', '江苏省',
'浙江省', '安徽省', '福建省', '江西省', '山东省',
'河南省','湖北省', '湖南省', '广东省', '广西壮族自治区',
'海南省', '重庆市', '四川省', '贵州省', '云南省',
'西藏自治区', '陕西省', '甘肃省', '青海省', '宁夏回族自治区',
'新疆维吾尔自治区', '香港特别行政区', '澳门特别行政区', '台湾省'
]
# 模拟省份对应某数据
data = [(province, random.randint(1, 600)) for province in provinces]
# 创建Map对象
map_chart = Map()
map_chart.add(
series_name='省级数据', # 数据系列名称
data_pair=data, # 数据对
maptype='china', # 指定地图类型
is_roam=True # 允许缩放和拖动地图
)
# 自定义formatter函数
def custom_formatter(params):
value = params.value
return f"{str(value)[:2]}" # 只显示数据的前两位
map_chart.set_series_opts(
label_opts=opts.LabelOpts(
font_size=11, # 设置标签字体大小
#formatter=custom_formatter # 使用自定义 formatter 函数,不生效。。
)
)
map_chart.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省数据分布"), # 设置地图的标题
visualmap_opts=opts.VisualMapOpts(max_=600), # 视觉映射配置,设置视觉映射最大值
)
# 生成高分辨率的图表并保存为HMTL文件
map_chart.render(path='map.html', pixel_ratio=2.0) # 设置像素比为2.0
# 将JavaScript加载到Jupyter中
map_chart.load_javascript()
和
# 在Jupyter中渲染图表
map_chart.render_notebook()
输出:
深入学习可以参考 pyecharts 官方图表示例。